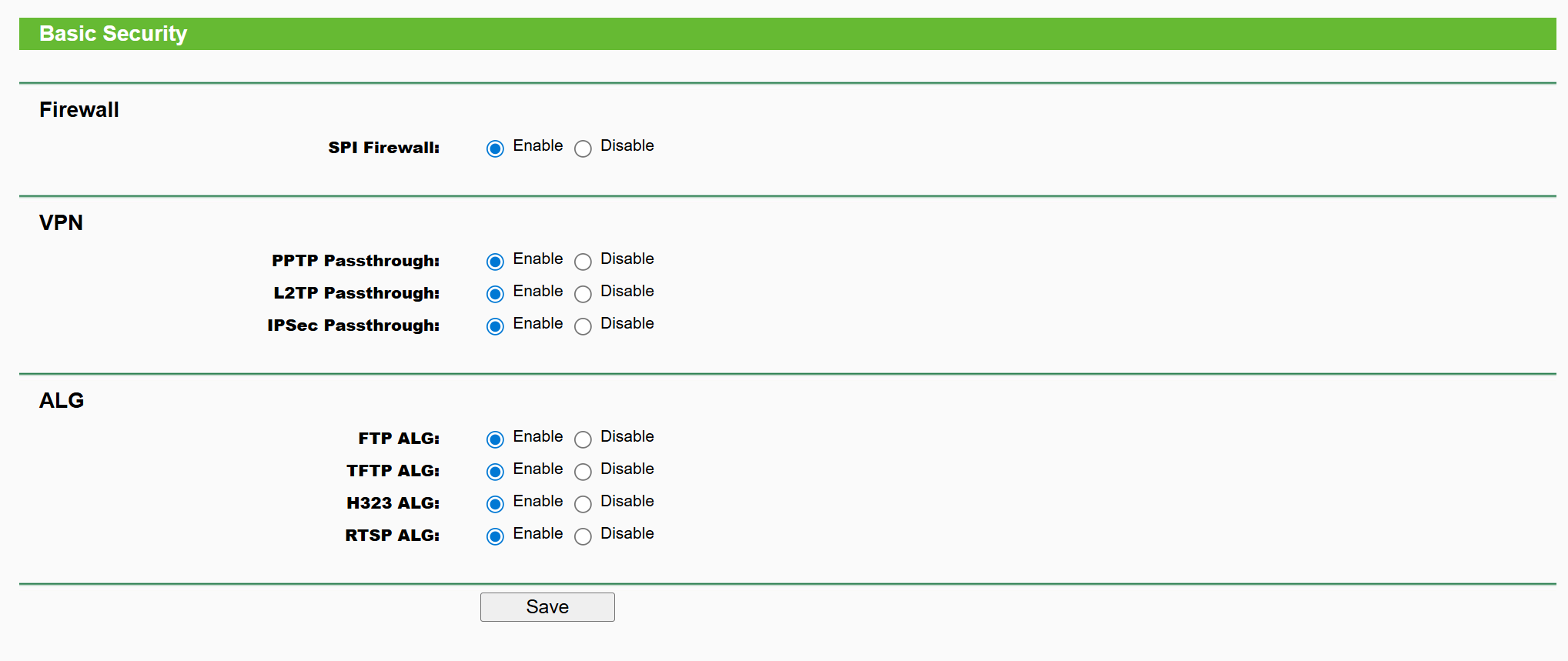
Get all the system info
systeminfo
Get RAM details
Get-CimInstance Win32_PhysicalMemory | Select-Object DeviceLocator, Manufacturer, @{Name="Capacity(GB)"; Expression={$_.Capacity / 1GB}}, ConfiguredClockSpeed
DeviceLocator Manufacturer Capacity(GB) ConfiguredClockSpeed
------------- ------------ ------------ --------------------
ChannelB-DIMM0 859B 16 2400
Get total expandable RAM
Get-CimInstance Win32_PhysicalMemoryArray | Select-Object MaxCapacity, MemoryDevices
MaxCapacity MemoryDevices
----------- -------------
33554432 2
Get SSD info
Get-PhysicalDisk | Select-Object FriendlyName, MediaType, HealthStatus, Size
FriendlyName MediaType HealthStatus Size
------------ --------- ------------ ----
KINGSTON SNVS500G SSD Healthy 500107862016
Get OS info
Get-ComputerInfo | Select-Object OSName, OSVersion, OSDisplayVersion, OSBuildNumber
OsName OsVersion OSDisplayVersion OsBuildNumber
------ --------- ---------------- -------------
Microsoft Windows 11 Pro 10.0.26100 24H2 26100
Get motherboard info
Get-CimInstance -ClassName Win32_BaseBoard | Select-Object Manufacturer, Product, SerialNumber, Version
Manufacturer Product SerialNumber Version
------------ ------- ------------ -------
AZW SEi CB1D27211C14S0696 Type2 - Board Version
Get CPU info
Get-CimInstance Win32_Processor | Select-Object Name, NumberOfCores, NumberOfLogicalProcessors, MaxClockSpeed
Name NumberOfCores NumberOfLogicalProcessors MaxClockSpeed
---- ------------- ------------------------- -------------
Intel(R) Core(TM) i5-8279U CPU @ 2.40GHz 4 8 2400
Get BIOS
Get-CimInstance Win32_BIOS | Select-Object Manufacturer, SMBIOSBIOSVersion, ReleaseDate
Manufacturer SMBIOSBIOSVersion ReleaseDate
------------ ----------------- -----------
INSYDE Corp. CB1D_FV106 8/24/2021 5:00:00 PM
Get networking info
Get-NetIPAddress -AddressFamily IPv4 | Select-Object InterfaceAlias, IPAddress
List installed software
Get-ItemProperty HKLM:\Software\Microsoft\Windows\CurrentVersion\Uninstall\* | Select-Object DisplayName, DisplayVersion, Publisher | Sort-Object DisplayName
Tip: Do not install wmic. It is deprecated. Use Powershell
List files in directory and order by file size descending (largest file first):
dir /O-S