Once I fixed the certificate so that it had Version 3 the error went away. To get a version 3 certificate, make sure you add the -extensions option to openssl ca command if you are using openssl ca to generate the certificate.
I used to wonder why Amazon is called a tech company and not a retail company? Why is Uber called a tech company and not a taxi company? Why is AirBnB called a tech company and not a hotel company?
The answer is because these companies view technology as the core of their business. Instead of outsourcing software development to Infosys, Wipro etc. or relying on 3rd party services, they hire FTEs and build huge engineering teams to develop the necessary technology in-house to power the business.
Example: Uber could have (or maybe they still are) used Google Maps to power their business – driving directions, location search, ETA etc. But they bid $3B (yes 3 billion) to try to acquire Nokia Maps [1]. Keep in mind this was just the acquisition cost. Imagine the YoY cost of just the resulting headcount itself – how would that compare to what Uber was/is paying YoY to Google Maps? [2] Another and even more audacious example: we know there will be self-driving cars in the future. Making cars is a car manufacturers job. All major car manufacturers will make autonomous driving cars in future. So why does Uber have to build a self-driving car in-house? Can’t they just buy self-driving cars when they hit the market as they undoubtedly will at some point? Tesla’s self-driving abilities are already impressive. Next step, after building out self-driving technology, is Uber also going to manufacture the cars themselves? Uber ATG reportedly costs the company $20M+ per month [3, 4].
Why do tech companies invest in technology so heavily when they could buy the thing from a vendor at presumably lower cost?
Definition: Consensus is the mechanism that
ensures all copies of a distributed ledger are the same i.e., at all times
I will have exactly the same copy of the ledger as you. This is critical –
imagine my copy of the ledger saying you owe me $100 bucks whereas your copy of
the ledger saying I owe you $100 bucks – and the ensuing mess.
Consensus is not a new thing that was invented with blockchain technology. It is an essential component of any distributed database (a distributed database is a database in which multiple copies of the database exist on multiple computers, referred to as nodes in literature) and algorithms for establishing consensus (Paxos, Raft, BFT, etc.) were developed in distributed systems literature way before blockchain was invented. I have to correct this. Raft was published 2014. Zab was published 2011. Original Bitcoin paper was published even before in 2009.
How does Hyperledger Fabric achieve consensus?
Hyperledger Fabric
achieves consensus through its ordering service. This service establishes a
total order on the transactions submitted to the network.
This is best illustrated
with the WhatsApp analogy. Have you ever used WhatsApp, Slack, Teams, HipChat,
RocketChat or another chat application where you received messages out of
order? What do we mean by out of order – it means the order in which you
received the messages was not the same as the order in which messages were
sent. It happened to me once when I was using the built-in chat in OfferUp to
communicate with a buyer. I sent two messages and the buyer received the one I
sent later first, followed by the one I sent first later. So the order in which
I sent messages was (A, B) but the receiver received the messages as (B, A).
Why does it happen? Imagine a chat room with
one hundred or a thousand participants. Messages are being generated at a fast
rate – lets say more than 10 per second. There are two architectures possible:
1) an architecture in which there is a backend server to which messages are
submitted; this server then announces availability of new messages to the
receivers (known as a broadcast) followed
by the receivers pulling the new messages from
the server. 2) Another way to architect the system is to implement a p2p network in which there is no central server.
Lets try to understand what happens in both
cases. In case of the central server, because of network latency it is possible that the order in
which the server will receive the messages is not the same as the order in
which messages were sent e.g., if a computer is geographically close to the
server, its message may arrive earlier than a computer who generated the
message first, but whose message has to travel a greater distance. This is not
the only factor. Its possible that the first computer may be on a higher
bandwidth connection than the second. Then, in practice if we consider a
large-scale system, there will not be a single backend server – the backend
server software would be running on multiple computers to divide and conquer
the flood of incoming messages. You might think that the problem can be avoided
by having a timestamp as part of the message when its generated on the client –
then the server can unambiguously determine which message came first. But think
about what will happen in practice. Lets say the server got a message A with
timestamp 12:00:00 and it broadcasted it to all the receivers. Then 3 minutes
later it got a message B with timestamp 11:57:00. It knows that B should come
before A but now it cannot undo the broadcast that has been done – it cannot
ask receivers to undo all the actions they may have taken as result of the
broadcast of A. To push it even further, in practice it is possible that the
clocks on different clients in different geographies and time zones won’t be in
sync with each other so one cannot rely on timestamps in messages to establish
chronological order of messages. And let’s not even involve this guy
(nevermind if you don’t get the prank).
In the other case of p2p network, the messages spread using a gossip protocol. Here it is even more likely that messages can arrive in different order on different nodes since the gossip involves periodic, pairwise, inter-process interactions with some form of randomness in the peer selection. Btw in case you didn’t notice, this is a new problem; in previous paragraph we were discussing messages arriving out of order on the server, but now we have switched to messages arriving in different order on different nodes.
In fact, this phenomenon of messages arriving in different order on different nodes happens
with Bitcoin also. Bitcoin protocol ensures that blocks are generated every 10
minutes or so with some spread. But still its possible for two blocks to be
generated very close to each other in (terms of time) and when that happens
depending on which block reaches a node first, there are temporary forks in the blockchain (also known as branches, illustrated graphically in this article). But then bitcoin protocol ensures
that only one branch will survive – the way it does this is by mandating that
in the presence of competing branches, all nodes have to select the longest
branch. And due to the nature of the system, it is guaranteed that a longest
branch will emerge eventually – read the probabilistic calculations in this article
for details. This is how Bitcoin achieves consensus. And also Ethereum.
Hyperledger Fabric achieves consensus in a
different way. It relies on a backend service (known as the ordering service)
that intermediates the messages between senders and
receivers. This backend service will ensure that all
receivers will see messages in same order – it follows that if all receivers see messages in same order, they
will perform the same actions/commits etc. Voila! consensus is
achieved. How does it do this? By using Apache Kafka, a widely used open source pubsub service developed much before blockchain
was invented. In fact I believe it is also used by applications like WhatsApp,
Slack, Teams etc. just for this very purpose – so that all clients see messages
coming in the same order and forms the backbone of these applications on the
backend. In case of applications like WhatsApp, its not a big deal if some
messages arrive in different order on different peers but it makes a big
difference in case of a blockchain where it can cause the ledger to fall out of
sync between peers.
The consensus mechanism is one of the key ways in which Hyperledger Fabric is different from other blockchains such as Bitcoin or Ethereum and its important to understand what it is and what it is not. For sometime I thought Fabric doesn’t really come with a consensus mechanism but that is not true. Fabric is using the intermediate server architecture we covered above where messages are sent to a server which then broadcasts the messages to receivers ensuring that all receivers will see the exact same order of messages. Btw, note that this order need not be the chronological order – in fact as we have seen above the concept of chronological order is not very well defined in a distributed system. It just needs to be a order – the simplest way to order messages is to order them in the order in which they are received on the server and this is exactly what the Solo orderer does. The Solo orderer is called so because it runs a single instance of the orderer and in this case it is trivial to establish a total order on messages. In practice in a production system, we don’t want a single point of failure and thus want to have more than one ordering node – that is where Apache Kafka is used. As explained in this article: “In Kafka, only the leader does the ordering and only the in-sync replicas can be voted as leader. This provides crash fault-tolerance (CFT) and finality happens in a matter of seconds. While Kafka is crash fault tolerant, it is not Byzantine fault tolerant, (BFT) which prevents the system from reaching agreement in the case of malicious or faulty nodes”. What it is saying is that there is a master node which does the ordering and if the master node fails, someone else is available to take over. This is known as crash fault tolerance. There is another, much more difficult, type of fault that is studied in distributed database replication – known as the Byzantine Fault. Kafka does not protect against that. For more details on Byzantine Fault refer to here and here.
Whereas Bitcoin and Ethereum use the p2p network without any intermediating service in
between who is in charge of establishing a total order on the transactions.
Incidentally this means the temporary forks in Bitcoin will never happen with
Hyperledger Fabric – a desirable property in enterprise applications I think.
With Bitcoin a seller has to wait for 6 blocks or 1 hour as a rule of thumb to
be sure that the payment made to them will end up in the blockchain [ref].
The ordering service is completely agnostic to
the contents of the messages – it does not look into the message to see what it
is. Thus it does not look or analyze in any way the read-write set produced by the endorsing peers.
Its sole purpose is to establish total order on the messages. Messages could be
thought of as events. Messages, transactions, events are all synonymous in this
discussion.
Few concluding notes: you may encounter articles on the web saying HL Fabric uses BFT or PBFT for consensus but that is not true and a result of people copying and pasting something they read on the internet without verifying the facts. I think part of this confusion arises from the fact that the Fabric whitepaper itself has been written so as to give the impression that Fabric uses BFT consensus – that is certainly the understanding I got from reading the paper – it is simply not true. As of this writing, Fabric (v1.4) uses Kafka for consensus. Kafka in turn uses Zookeeper to achieve consensus. And Zookeeper’s consensus is based on the Zookeeper Atomic Broadcast (ZAB). So ZAB really is the consensus algorithm behind Fabric. Upcoming versions of Fabric will replace Kafka with Raft – another protocol to achieve consensus. The work is being tracked here. Also read ordering-faqs. Also some articles on the web will state Fabric’s consensus protocol is pluggable – while this is not incorrect, it is easier said than done. If you want to use a protocol other than Solo or Kafka, you will have to write your own plugin and compile your own custom binary of fabric-orderer. For details refer to the question titled “I want to write a consensus implementation for Fabric. Where do I begin?” in the orderer-faqs.
PS: More details can be found in my book on Hyperledger Fabric. For even further reading, check out the paper on Calvin published in 2012. You can draw a lot of parallels between Calvin and Hyperledger Fabric.
_The donkey said to the tiger, ‘The grass is blue.’ Tiger said, ‘No grass is green.’_
_Then the discussion between the two became intense. Both of them are firm in their own words. To end this controversy, both went to Lion – King of Jungle._
_In the middle of the animal kingdom, sitting on the throne was a lion. The donkey started yelling before the tiger could say anything. “Your Highness, the grass is blue, isn’t it?” Lion said, ‘Yes! The grass is blue.’_
_Donkey, ‘This tiger does not believe. Annoys me He should be punished properly. ‘ The king declared, ‘Tiger will be jailed for a year. King’s verdict was heard by donkey and he was jumping in joy in entire jungle. The tiger was sentenced to one-year jail.’_
_The Tiger went to the Lion and asked, ‘Why Your Highness! Grass is green, isn’t it? ‘ Lion said, ‘Yes! Grass is green.’ Tiger said, ‘… then why am I sentenced to jail?’_
_*Lion said, “you did not get punished for the grass being blue Or green. You have been punished for debating with that stupid donkey. Brave and intelligent creatures like you have argued with a donkey and have come here to get a decision”_*
Do not buy USD from airport. We purchased USD at delhi airport from PNB on 2/18 IST and were given an exchange rate of 76.13 plus flat Rs. 45 transaction fee (CGST+SGST) when the true rate was 71.36. So this is a premium of 106.68% reflecting approx. 7% commission. Buy USD from bank prior to departure date.
If you are travelling with children esp. infants then 3 hour layover for connecting flight is recommended. Less than 2h layover is risky and you may miss connecting flight.
Below are travel times of some flights
DEL-SEA
SEA-DEL
Delta/KLM
20H30M
19H24M
Emirates
21H30M
21H10M
BA/AA
22H10M
21H30M
ANA
22H45M
21H55M
Lufthansa/United
21H35M
22H35M
AirCanada
17H19M
19H00M
Asiana
23H30M
22H10M
Notes on Lufthansa: – Lufthansa charges approx. $60 extra to choose seats per leg. So for a round trip from India to US that means 60*4=$240 if you want to choose your seats. Their policy may change. – Security check in FRA is tight and they do physical frisking
Objective: Understand how fabric-ca-server works and run it with user supplied X509 certificate and key.
Lets spin up a docker instance of fabric-ca-server. If you spin up an instance without overriding the entrypoint, the server would already have started because of following code in the fabric-ca docker image:
“Cmd”: [
“/bin/sh”,
“-c”,
“fabric-ca-server start -b admin:adminpw”
]
In this tutorial, since we want to understand how it works behind the covers, we will start it with following command instead:
In above we had already created a network named dscsa_net earlier. The tail -f /dev/null is simply to make it enter infinite loop since otherwise the container will immediately exit. Now we can enter the container like follows:
$ docker exec -it <CONTAINER-ID> /bin/bash
where you can get the CONTAINER-ID by running docker ps. Next verify version
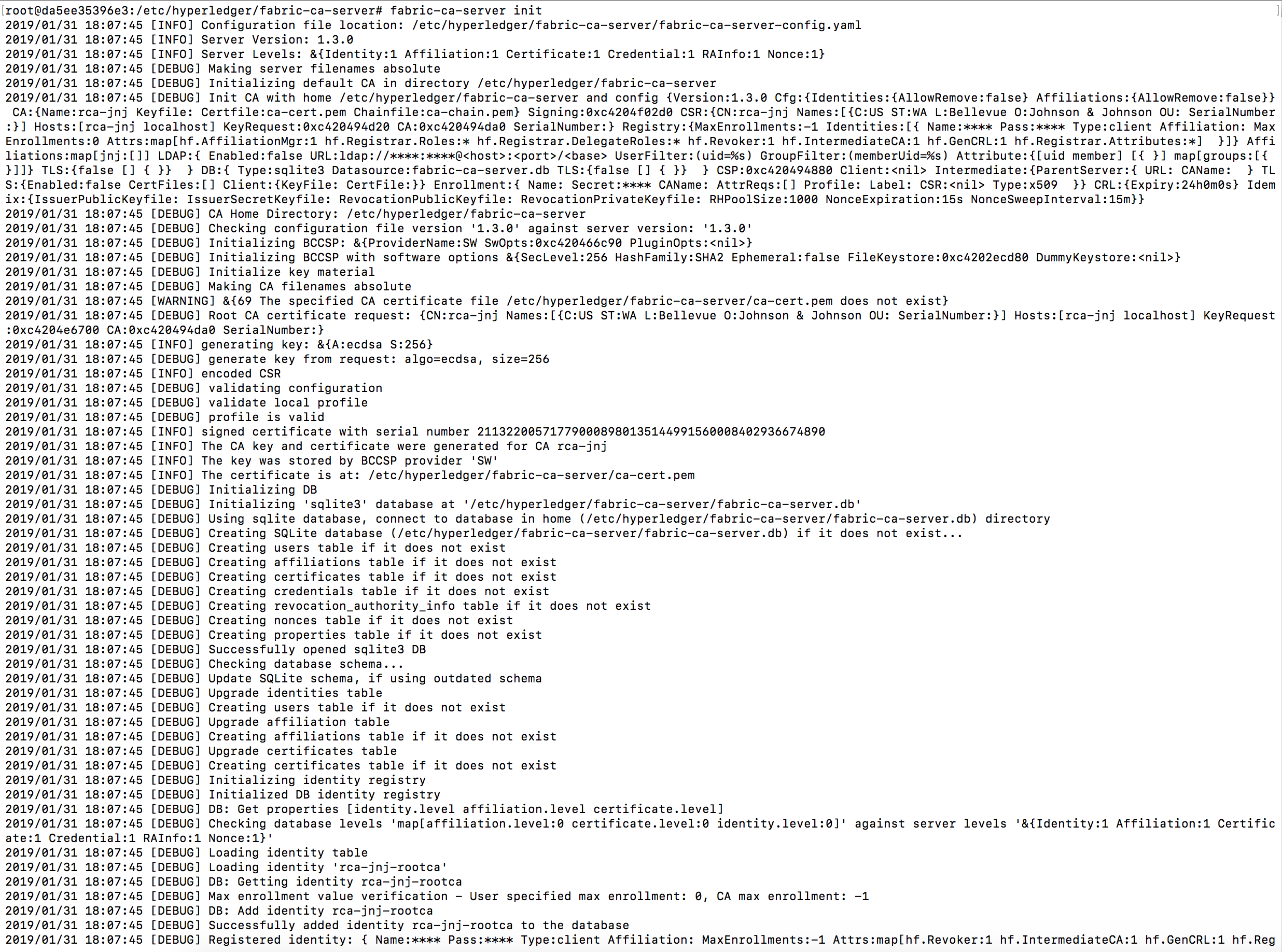
root@da5ee35396e3:/etc/hyperledger/fabric-ca-server# fabric-ca-server version
fabric-ca-server:
Version: 1.3.0
Go version: go1.10.4
OS/Arch: linux/amd64
Next verify there are only 2 files in the /etc/hyperledger/fabric-ca-server directory – ca-cert.pem and ca-key.pem
root@da5ee35396e3:/etc/hyperledger/fabric-ca-server# ls -al
total 40
drwxr-xr-x 1 root root 4096 Jan 31 18:07 .
drwxr-xr-x 1 root root 4096 Oct 10 14:56 ..
-rw-rw-r– 1 1001 1001 887 Oct 10 14:53 ca-cert.pem
2019/01/31 18:07:45 [INFO] Initialized sqlite3 database at /etc/hyperledger/fabric-ca-server/fabric-ca-server.db
2019/01/31 18:07:45 [INFO] The issuer key was successfully stored. The public key is at: /etc/hyperledger/fabric-ca-server/IssuerPublicKey, secret key is at: /etc/hyperledger/fabric-ca-server/msp/keystore/IssuerSecretKey
Hopefully it succeeds, and now if you ls you should see something like following:
root@da5ee35396e3:/etc/hyperledger/fabric-ca-server# ls
Crack open the ca-cert.pem by running `openssl x509 -in ca-cert.pem -text -noout` and verify it looks good.
Even though the logs say secret key is at: /etc/hyperledger/fabric-ca-server/msp/keystore/IssuerSecretKey, the private key will be stored under msp/keystore/<long-filename-with-suffix-_sk>
Now copy the public certificate ca-cert.pem and private key file to the host machine using docker cp once again.
Kill the service. docker service rm <SERVICE-NAME>
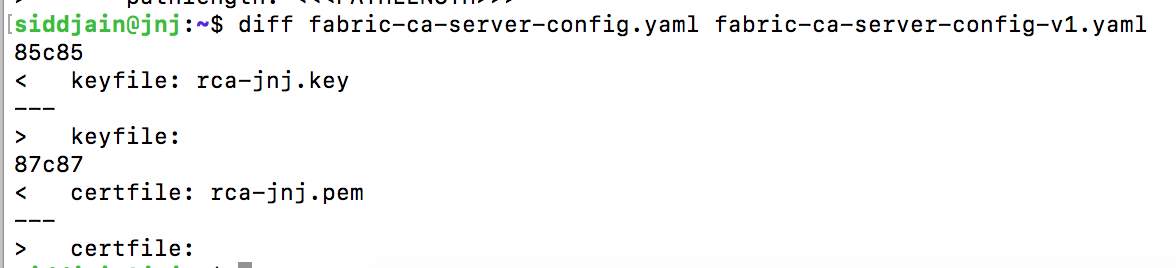
Next we will restart fabric-ca-server but this time make it use the certificate and keyfile we got above. To do this, we need to edit the ca section of fabric-ca-server-config.yaml like so:
where use the names of your own files.
Next restart fabric-ca-server, delete the .pem files in $FABRIC_CA_SERVER_HOME directory, copy the yaml file and the public-private keys (so total 3 files) over to $FABRIC_CA_SERVER_HOME and run fabric-ca-server init. This time it will not generate new certificate and key and instead use the cert and key that you have supplied. In practice when the server is restarted (e.g., the VM gets rebooted) you will need to use the previous cert and key otherwise the blockchain will not work any more (I am not sure about this. It is to be verified) since the cert in genesis block will not match anymore.
root@684ac3891b78:/etc/hyperledger/fabric-ca-server# ls
You can diff your private key against the keyfile under map/keystore/<long-filename-with-suffix-_sk> and verify they should be the same.
More fun and profit: copy the fabric-ca-server.db to the host. Install sqlite by running $ sudo apt-get install sqlite3 libsqlite3-dev. Then open the db file by running $ sqlite3 fabric-ca-server.db
sqlite> .tables
affiliations properties
certificates revocation_authority_info
credentials users
nonces
sqlite> .schema users
CREATE TABLE users (id VARCHAR(255), token bytea, type VARCHAR(256), affiliation VARCHAR(1024), attributes TEXT, state INTEGER, max_enrollments INTEGER, level INTEGER DEFAULT 0);
do select * from users; to print contents of users table etc.
Got this error trying to launch a docker service. After some searching came across this link. Indeed the docker from snap is broken. Once I installed using official steps, the error wen’t away. Please don’t install docker using `sudo snap install docker`.
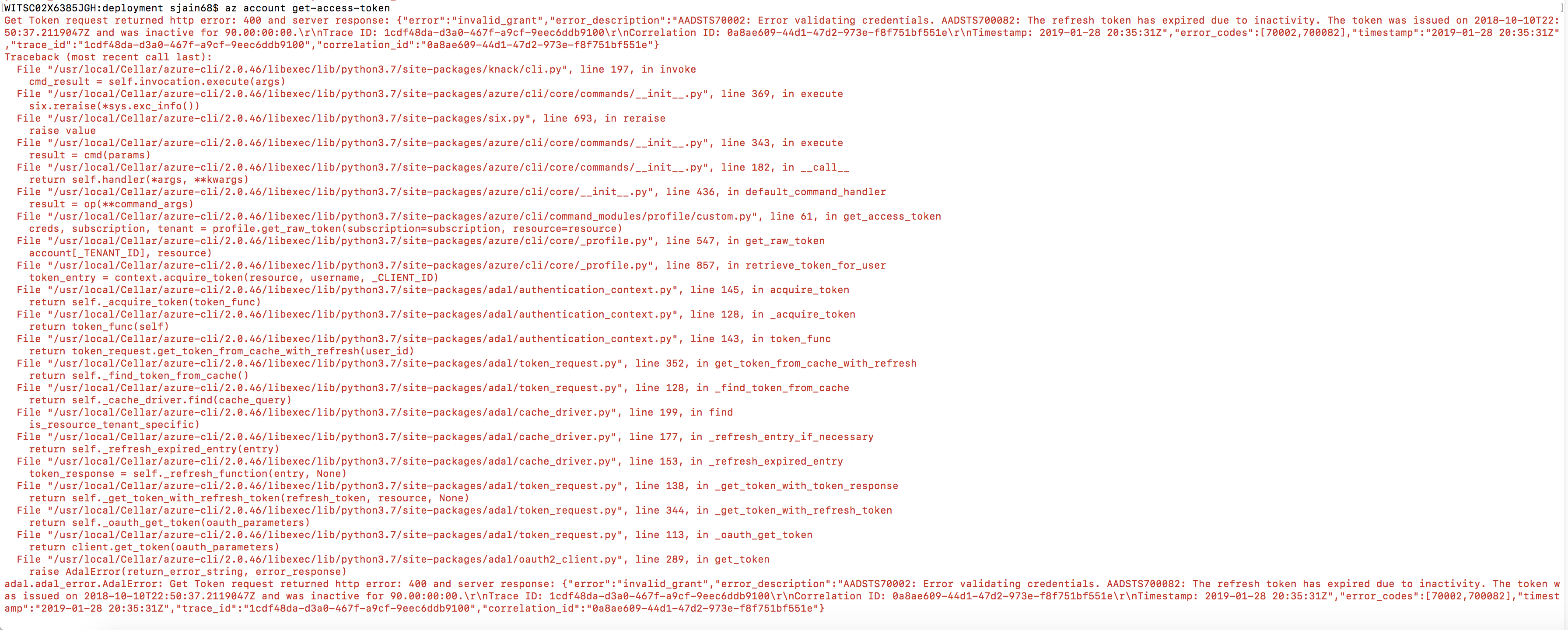
Sometimes you will get this error when trying to run az CLI. My first attempt to fix it was to refresh the token using az account get-access-token but when I ran it, it gave this:
Get Token request returned http error: 400 and server response: {“error”:”invalid_grant”,”error_description”:”AADSTS70002: Error validating credentials. AADSTS700082: The refresh token has expired due to inactivity. The token was issued on 2018-10-10T22:50:37.2119047Z and was inactive for 90.00:00:00.\r\nTrace ID: 2d6dfd99-0307-4f8d-a5d7-f259b6f51000\r\nCorrelation ID: 6876283d-f5a2-4dfc-9549-882b750f60bb\r\nTimestamp: 2019-01-28 21:00:43Z”,”error_codes”:[70002,700082],”timestamp”:”2019-01-28 21:00:43Z”,”trace_id”:”2d6dfd99-0307-4f8d-a5d7-f259b6f51000″,”correlation_id”:”6876283d-f5a2-4dfc-9549-882b750f60bb”}
The solution is to run az login to refresh the token.