1. Abstract
This article is my attempt to explain and understand what is quantum computing. As I am new to the subject and learning it myself, the information contained in the article could be potentially wrong. But it would be an interesting exercise to write this brief article documenting what I think it is – based on just a few hours of reading a book – and see if my understanding was correct as time passes by and I learn more about the subject.
2. So what is it?
I’d like to give the analogy of Fourier Optics as for me analogies are the best way I understand things. From Wikipedia, see the section titled Fourier transforming property of lenses: If a transmissive object is placed one focal length in front of a lens, then its Fourier transform will be formed one focal length behind the lens. So if you want to compute a 2D Fourier Transform (FT) you could do it the conventional way where you write some code in your favorite programming language, run it on a computer and get the result. Or another way to “compute” the FT would be to use a lens and its Fourier transforming property. The Wikipedia article goes on: “All FT components are computed simultaneously – in parallel – at the speed of light. As an example, light travels at a speed of roughly 1 ft (0.30 m) / ns, so if a lens has a 1 ft (0.30 m) focal length, an entire 2D FT can be computed in about 2 ns (2 x 10−9 seconds). If the focal length is 1 in., then the time is under 200 ps. No electronic computer can compete with these kinds of numbers or perhaps ever hope to, although supercomputers may actually prove faster than optics, as improbable as that may seem. However, their speed is obtained by combining numerous computers which, individually, are still slower than optics.”
Quantum Computing is completely analogous. The behavior/evolution of quantum particles or a quantum system can be described by operation of matrices – linear algebra. The equations governing quantum mechanics are linear – that is why a quantum particle or system can exist in superposition of states because for a linear equation if X and Y are solutions, then any linear combination of X and Y is also a solution. So say you have a problem which requires you to calculate something which is nothing but basically a sequence of special matrix operations. You could do it the conventional way, or if you could build a quantum system (circuit), you could let it evolve and monitor (measure) it to get the answer – that is basically a quantum computer.
Conventional computers are Turing machines which evaluate Boolean logic. Quantum computers evaluate matrix operations and using the property of entanglement they can run many inputs in parallel. Boolean logic is composed of a handful of operators – OR, AND, NOT and combinations of those. In case of QC we have special matrices that form the building blocks. Conventional computers speak the language of Boolean Logic. Quantum Computers speak and understand the language of matrix computations.
There are two things from which quantum computers derive all their power – superposition and entanglement.
3. Challenges
The challenge with QC is that building a quantum system is hard and the difficulty increases as the number of particles (i.e., number of qubits) to be entangled increases. The system can quickly get disentangled due to decoherence so the challenge is in being able to build and control the system. This is the hardware challenge. Another challenge is finding useful problems that can be expressed as quantum computations. Computing 2D FT is is very useful problem in image processing. We need to find useful problems that can be expressed as quantum (err.. matrix) computations. This is the software challenge.
A bibliography of quantum algorithms is available at https://quantumalgorithmzoo.org/ – these are essentially the use-cases. If you have a problem that can be reduced or mapped to one of these cases, then you can use a QC to solve it. However there is a catch here that many algorithms require using a number of qubits which is out of reach of today’s quantum computers. E.g., Shor’s algorithm for factorization is a famous example of quantum computation that can be used to break RSA cryptography. But it requires a # of qubits which is out of reach of today’s QC. The hardware challenge is being solved by companies like Google and IBM. They will make quantum computers and make them accessible via the cloud just like we can access GPU and other beefy machines today using AWS or other cloud providers.
One of the things I have noticed in my limited exploration of this topic is that the current software libraries for quantum computation (Google’s Cirq and Microsoft’s Q# are some examples) are high-level languages but the code is written to express a “low-level” quantum circuit. Its like asking you to program a classical computer by writing code to create the underlying Boolean Logic circuit – no one does that these days. I wonder if in future the libraries will evolve so that one does not have to write a “low-level” circuit. Maybe its the way it is because quantum computer has an advantage over classical computer only when the computation can be expressed as a quantum circuit – basically a sequence or flowchart of special matrix operations – special because not every matrix operation is qualified to be permitted in a quantum circuit. Only special matrix operations are permitted – in particular the matrices must be invertible.
4. What does Google’s recent Quantum Supremacy claim mean?
Google’s recent announcement of Quantum Supremacy made big news every where. What is it about? It basically demonstrated that they were able to build a 54-qubit processor and put it to some use. Its about the hardware challenge. Building a QC becomes very difficult as the number of qubits increase because its very difficult to keep them entangled and pure and prevent them from getting disentangled as the computation progresses (the depth of the circuit). The problem they solved was not interesting per se – they sampled the probability distribution resulting from a random circuit. The input to the problem is a state vector that can take on 2n possible values where n is the number of qubits. This state vector essentially undergoes transformation by a random quantum circuit to yield the output vector. This output vector can be in so many states and we are interested in finding or rather sampling from its probability distribution. Google team did this computation using both a quantum computer as well as a classical computer. They then compared result of QC with result of classical computer to validate and verify that the QC was giving correct results – this would not have happened if the qubits had gotten disentangled. Sotheir achievement was in being able to demonstrate a system that could control and keep 54 qubits in entanglement through the course (depth) of their circuit. Ultimately as n increases they reach a point where classical calculation becomes infeasible.
5. Quantum Computing: Pop Quiz
Think you understand quantum computing. See if you can answer following question:
In QC, it is said that the quantum state of N qubits can be expressed as a vector in a space of dimension 2N. E.g., if you have 1 qubit there are two state vectors (0,1) and (1,0) which are written as |0> and |1> respectively. For a system of 2 qubits, there are 4 state vectors (0,0,0,1), (0,0,1,0), (0,1,0,0) and (1,0,0,0) written as |00>, |01>, |10>, |11>. Note that in each case, all entries are zero except 1. 2N seems like a big space but given a vector in this space – all components will be zero except 1. So there are only 2N possible values the state vector can take. So why don’t we say the space is N dimensional? A N-bit string has 2N possible values. To make the question more provocative, the total memory required to store the state vector is claimed to be of the order of 2N. This quickly becomes out of reach when we try to do classical simulation and is at the heart of Google’s Quantum Supremacy. For system of only 50 qubits we would need petabytes of storage to store the state vector. But we only need N bits to store the position of the 1 in the state vector – rest all entries are zero. So what gives?


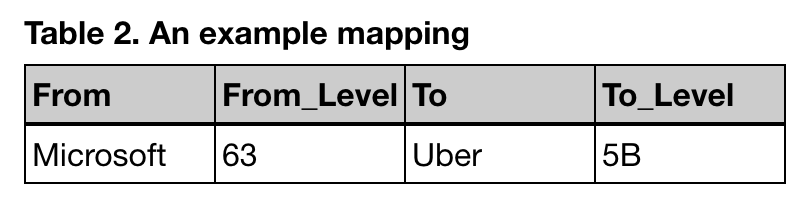
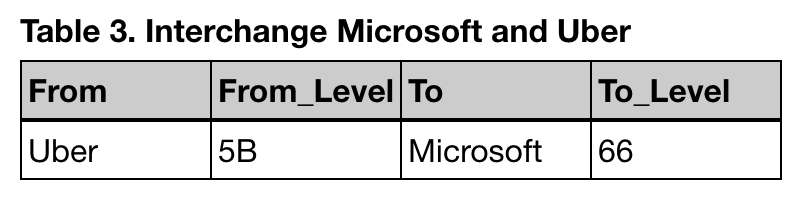
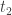 for money withdrawn from 401k (the expectation is that you will be in a lower tax bracket during retirement) and
for money withdrawn from 401k (the expectation is that you will be in a lower tax bracket during retirement) and to denote the expenses in a year. These expenses need to be deducted from the amount that is invested in the ordinary non-tax sheltered account.
to denote the expenses in a year. These expenses need to be deducted from the amount that is invested in the ordinary non-tax sheltered account.
 is a function that computes tax on
is a function that computes tax on  , and
, and is the reduced rate of return that money in non-tax sheltered account earns
is the reduced rate of return that money in non-tax sheltered account earns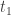 will be the marginal tax rate (bracket)
will be the marginal tax rate (bracket)

 is simply the function which computes tax, so
is simply the function which computes tax, so  giving
giving

 (i.e., better to invest in Roth), we get a simple formula
(i.e., better to invest in Roth), we get a simple formula
 is a function of
is a function of  have cancelled out and we see that the factors that influence whether you should choose Roth vs. Traditional 401k are:
have cancelled out and we see that the factors that influence whether you should choose Roth vs. Traditional 401k are:


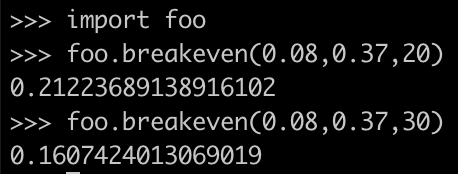
 and two different values of
and two different values of 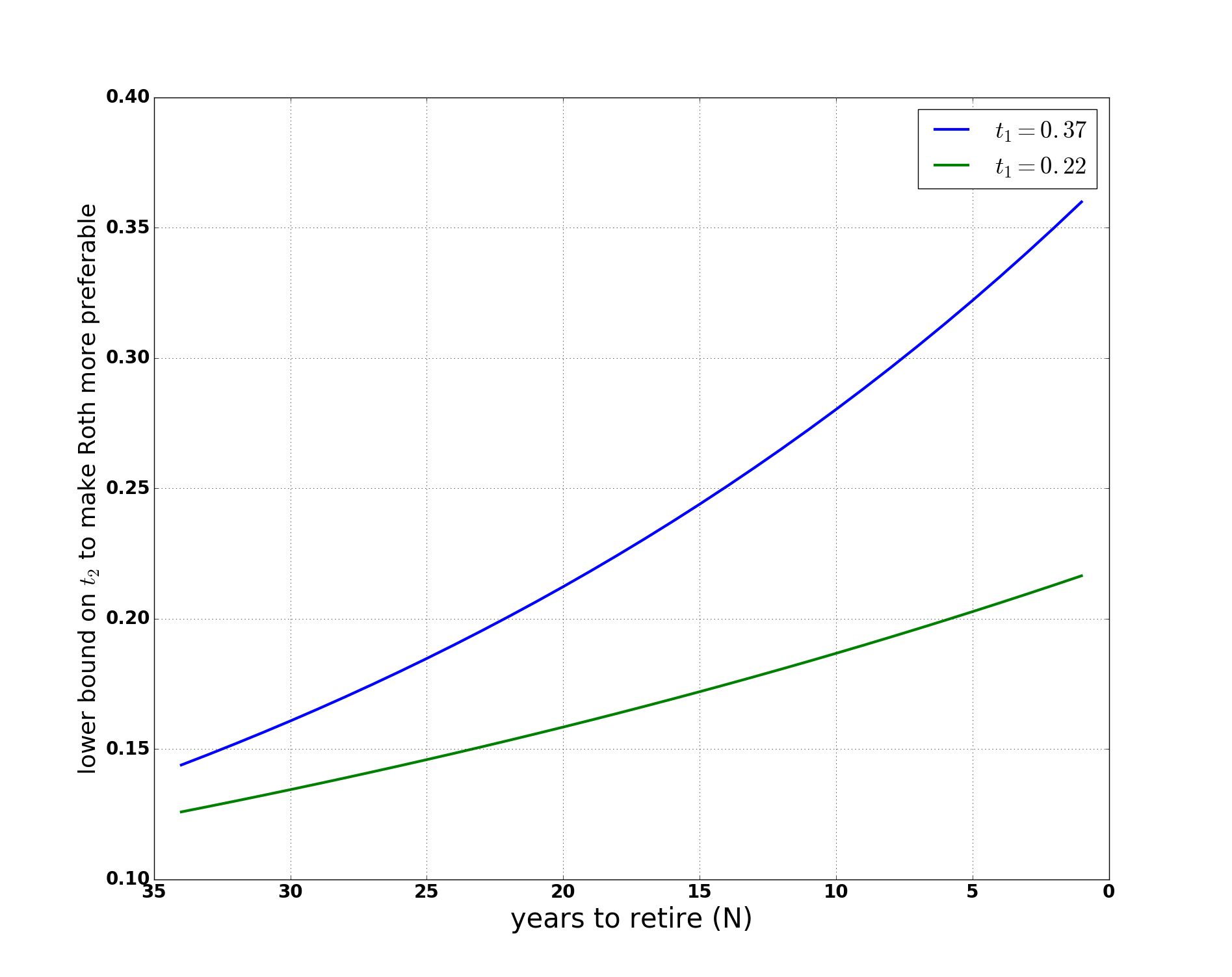
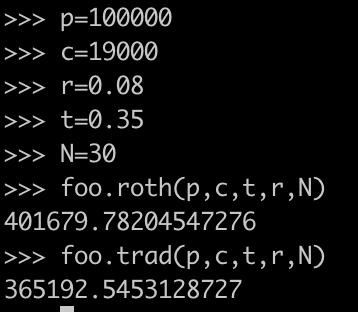
 = principal amount = salary earned in a year = $100,000 as example
= principal amount = salary earned in a year = $100,000 as example = contribution amount to 401k = $19,000 for 2019 whether it be roth or traditional
= contribution amount to 401k = $19,000 for 2019 whether it be roth or traditional = tax rate = 0.35 as example
= tax rate = 0.35 as example in ordinary account. Next we pay tax on the full
in ordinary account. Next we pay tax on the full  . Call this
. Call this  . This amount can be invested just like we invest the money in a 401k. The only difference is that in ordinary account we will have to pay tax on earnings every year. I leave it as an exercise for reader to prove that the annual tax incurred in the ordinary account basically has the effect of reducing
. This amount can be invested just like we invest the money in a 401k. The only difference is that in ordinary account we will have to pay tax on earnings every year. I leave it as an exercise for reader to prove that the annual tax incurred in the ordinary account basically has the effect of reducing 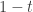 so that at end of
so that at end of  . The money in 401k grows as
. The money in 401k grows as  and can be withdrawn tax free. So at the end we have
and can be withdrawn tax free. So at the end we have
 . This becomes the new
. This becomes the new 
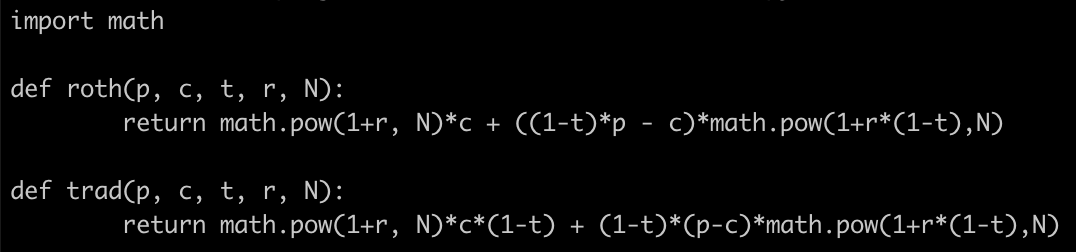
 . After
. After  which you can withdraw tax free.
which you can withdraw tax free. . Now when you withdraw it, you pay tax and so the net amount becomes
. Now when you withdraw it, you pay tax and so the net amount becomes  which is same as earlier.
which is same as earlier.