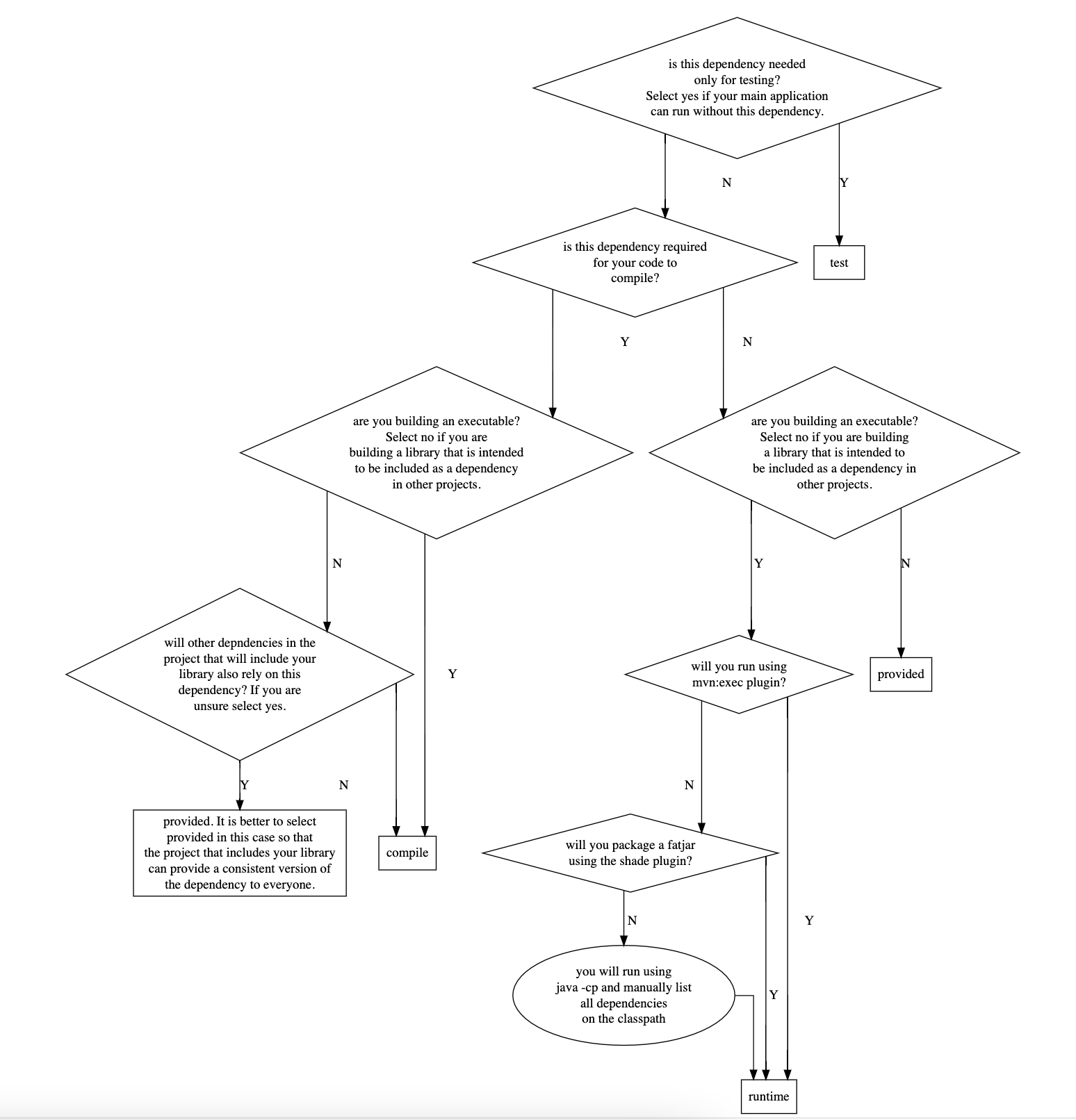
- Get/Set current project
gcloud config get-value project
gcloud config set project XXX
2. Login using a service account
gcloud auth activate-service-account --key-file=keyfiles/gcp.json
You shouldn’t do this however. Quoting best practices:
Don’t use service accounts during development. During your daily work, you might use tools such as the Google Cloud CLI, gsutil, or terraform. Don’t use a service account to run these tools. Instead, let them use your credentials by running gcloud auth login (for the gcloud CLI and gsutil) or gcloud auth application-default login (for terraform and other third-party tools) first.
3. Get access token of currently logged in user:
gcloud auth application-default print-access-token
You can also see the application default credentials by opening $HOME/.config/gcloud/application_default_credentials.json. Get the identity token by running:
gcloud auth print-identity-token
Refer this for the difference between access token and identity token.
4. Get metadata about compute projects:
gcloud compute project-info describe --format=json
5. Add metadata to compute project:
gcloud compute project-info add-metadata \
--metadata enable-oslogin=FALSE \
--project=xxx
6. Add ssh key to os-login
gcloud compute os-login ssh-keys add \
--key-file=/Users/me/.ssh/id_rsa.pub \
--project=xx \
--ttl=999d
Although os-login is recommended, I couldn’t get it to work.
7. To update ssh config
gcloud compute config-ssh --project=xxx
8. Create service account and assign bigquery.dataEditor and bigquery.jobUser roles:
gcloud iam service-accounts create ${ACCTNAME} --description="Service Account"
gcloud iam service-accounts keys create keyfile.json \
--iam-account ${ACCTNAME}@${PROJECT}.iam.gserviceaccount.com
for role in roles/bigquery.dataEditor roles/bigquery.jobUser; do
gcloud projects add-iam-policy-binding ${PROJECT} \
--member serviceAccount:${ACCTNAME}@${PROJECT}.iam.gserviceaccount.com --role ${role}
done
9. To update gcloud SDK to latest version, run:
$ gcloud components update
10. To install or remove specific components, run:
$ gcloud components install COMPONENT_ID
$ gcloud components remove COMPONENT_ID
11. Run gcloud cheat-sheet to see a roster of go-to gcloud commands. Also refer this.
12. To setup a Python development environment see this. Google recommends that you always use a per-project virtual environment when developing locally with Python. When the gcloud SDK is installed, it sets up its own venv which can be found at ~/.config/gcloud/virtenv
13. scp files from a VM to local computer using gcloud:
$ gcloud compute scp --project=xxx INSTANCE_NAME:/path/to/location/\*.sh /path/to/local
Above will copy all files ending in .sh. We have to escape the asterisk using backslash otherwiese you get an error. see this.
14. create a secret
gcloud secrets create my-database-password --replication-policy="automatic" --project=my-gcp-project
echo -n "xxx" | gcloud secrets versions add my-database-password --data-file=- --project=my-gcp-project
verify:
gcloud secrets versions access 1 --secret="my-database-password" --project=my-gcp-project
15. Get path of google cloud sdk
$ gcloud info --format="value(installation.sdk_root)"
/usr/lib/google-cloud-sdk
16. Who am I? What identity are you using to authenticate against GCP?
$ gcloud config list account --format "value(core.account)"
Best Practices
- When your code is running in a local development environment, such as a development workstation, the best option is to use credentials associated with your Google Account, also called user credentials. You should NOT set the
GOOGLE_APPLICATION_CREDENTIALS environment variable during local development because: Make sure that the GOOGLE_APPLICATION_CREDENTIALS environment variable is set only if you are using a service account key or other JSON file for ADC. The credentials pointed to by the environment variable take precedence over other credentials, including for Workload Identity.
- Never set
GOOGLE_APPLICATION_CREDENTIALS as an environment variable on a Cloud Run service. Always configure a user-managed service account instead.
Adding disks to a VM using command line
Step 1: add the disk (here we are adding a 300GB disk):
gcloud compute disks create disk-1 --project=xxx --type=pd-balanced --size=300GB --zone=us-central1-a
Step 2: Attach the disk to the VM:
gcloud compute instances attach-disk instance-1 --disk disk-1 --project=xxx
Step 3: Format and Mount
Use instructions available here
Step 4 (Optional): Create backup policy. Here we are setting up a policy to perform daily backups (snapshots). Snapshots will be retained for 14 days:
gcloud compute resource-policies create snapshot-schedule default-schedule-1 --project=xxx --region=us-central1 --max-retention-days=14 --on-source-disk-delete=keep-auto-snapshots --daily-schedule --start-time=14:00
It will respond with a message:
Created [https://www.googleapis.com/compute/v1/projects/xxx/regions/us-central1/resourcePolicies/default-schedule-1]
Step 5 (Optional): Enforce the policy:
gcloud compute disks add-resource-policies disk-1 --project=xxx --zone=us-central1-a --resource-policies=default-schedule-1
Be careful to use the same qualifier (label) that you used in Step 4. In above the qualifier is default-schedule-1.
How to I login to Cloud SQL using my GCP user account (xyz@yahoo.com)?
Pre-requisites (one-time setup): First you need to setup SSL authentication on the server (steps for this are not covered here). Then:
gcloud sql instances patch $INSTANCE_NAME \
--database-flags=cloudsql.iam_authentication=on
gcloud sql users create $YOUR_EMAIL_ADDRESS \
--instance=$INSTANCE_NAME \
--type=cloud_iam_user
After that to login using your GCP account:
PGPASSWORD=$(gcloud sql generate-login-token) psql \
"sslmode=verify-ca \
sslrootcert=/path/to/server.pem \
sslcert=/path/to/client-cert.pem \
sslkey=/path/to/client-key.pem \
hostaddr=x.x.x.x \
user=$YOUR_EMAIL_ADDRESS \
dbname=$DATABASE"
How do I see all the settings of Cloud SQL Postgres server?
PGPASSWORD=xxx psql \
"sslmode=verify-ca \
sslrootcert=/path/to/server.pem \
sslcert=/path/to/client-cert.pem \
sslkey=/path/to/client-key.pem \
hostaddr=x.x.x.x \
user=$USER \
dbname=$DATABASE" -c "SELECT name, setting FROM pg_settings" | cat
There are some settings above does not cover. You can get those by running:
gcloud sql instances describe $INSTANCE_NAME