This post summarizes results of a performance test to compare BigQuery vs. Clickhouse – two high-performance analytics databases. Later on I performed same tests on DuckDB but as we shall see it cannot compete with CH or BQ so main focus will be on BQ vs CH.
Methodology
Star Schema Benchmark was used for the test. dbgen tool (commit 0741e06d4c3e811bcec233378a39db2fc0be5d79) was run with a SF of 333 to generate the dataset. Here are the details:
| Table | # of rows |
| customer.tbl | 9,990,000 |
| supplier.tbl | 666,000 |
| part.tbl | 1,800,000 |
| date.tbl | 2,556 |
| lineorder.tbl | 1,997,997,687 |
All in all this generated about 225 GB of data. Clickhouse loaded all the 2B rows in an impressive 30 min time period.
$ time clickhouse-client --password --query "INSERT INTO ssb.lineorder FORMAT CSV" < /app/ssb-data/lineorder.tbl
Password for user (default):
real 29m56.227s
user 94m10.616s
sys 5m7.183s
After this the queries described at [1] were run on BigQuery and Clickhouse. In case of BigQuery, the SQL code needs to be adapted as follows:
| Clickhouse | BigQuery | DuckDB |
| PARTITION BY toYear(LO_ORDERDATE) | partition by date_trunc(lo_orderdate, year) | partition clause is not supported while creating table |
| ORDER BY (LO_ORDERDATE, LO_ORDERKEY) | cluster BY LO_ORDERDATE, LO_ORDERKEY | order by clause is not supported while creating table |
| toYear(LO_ORDERDATE) = 1993 | extract(year from LO_ORDERDATE) = 1993 | extract(year from LO_ORDERDATE) = 1993 |
| toISOWeek(LO_ORDERDATE) = 6 | extract(ISOWeek from LO_ORDERDATE) = 6 | week(LO_ORDERDATE) = 6 |
| toYYYYMM(LO_ORDERDATE) = 199712 | extract(year from LO_ORDERDATE) = 1997 and extract(month from LO_ORDERDATE) = 12 | extract(year from LO_ORDERDATE) = 1997 and extract(month from LO_ORDERDATE) = 12 |
The first thing which impressed me is that the raw CSV lineorder table measured 239,234,458,925 bytes but it got reduced to 57 GB when ingested into Clickhouse and 48 GB in case of BigQuery
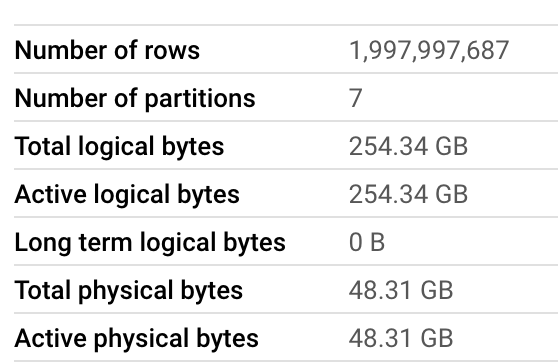
The denormalized lineorder_flat table has following stats in BQ:
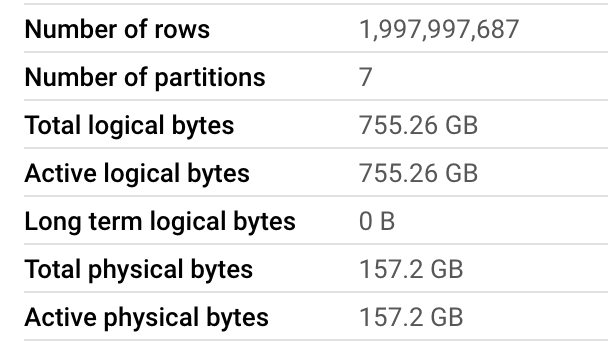
In case of Clickhouse, running this script gave us:
┌─parts.database─┬─parts.table─────────────┬───────rows─┬─latest_modification─┬─disk_size──┬─primary_keys_size─┬─engine────┬───bytes_size─┬─compressed_size─┬─uncompressed_size─┬────────────────ratio─┐
│ ssb │ lineorder_flat │ 1997997687 │ 2022-10-15 01:13:59 │ 178.38 GiB │ 1.40 MiB │ MergeTree │ 191538385255 │ 178.09 GiB │ 323.22 GiB │ 0.5510020049576446 │
│ ssb │ lineorder │ 1997997687 │ 2022-10-17 05:22:17 │ 55.59 GiB │ 1.40 MiB │ MergeTree │ 59685552796 │ 55.47 GiB │ 80.01 GiB │ 0.693277565266494 │
│ ssb │ customer │ 9990000 │ 2022-10-14 02:26:59 │ 382.37 MiB │ 4.79 KiB │ MergeTree │ 400943880 │ 382.03 MiB │ 562.22 MiB │ 0.6795006124121903 │
│ system │ trace_log │ 3652777 │ 2022-10-17 17:46:08 │ 58.67 MiB │ 2.69 KiB │ MergeTree │ 61520620 │ 58.15 MiB │ 1.06 GiB │ 0.05349937527433843 │
│ ssb │ part │ 1800000 │ 2022-10-14 02:27:57 │ 31.03 MiB │ 892.00 B │ MergeTree │ 32541446 │ 30.96 MiB │ 44.07 MiB │ 0.7024153306907351 │
│ system │ asynchronous_metric_log │ 78135224 │ 2022-10-17 17:46:13 │ 28.09 MiB │ 95.36 KiB │ MergeTree │ 29458819 │ 26.76 MiB │ 1.10 GiB │ 0.02382792149791971 │
│ system │ metric_log │ 295379 │ 2022-10-17 17:46:09 │ 27.12 MiB │ 696.00 B │ MergeTree │ 28442229 │ 25.86 MiB │ 1.02 GiB │ 0.024746974449290835 │
│ ssb │ supplier │ 666000 │ 2022-10-14 02:28:33 │ 25.10 MiB │ 332.00 B │ MergeTree │ 26323607 │ 25.08 MiB │ 36.85 MiB │ 0.6807884856313037 │
│ system │ part_log │ 35368 │ 2022-10-17 06:14:37 │ 1.36 MiB │ 48.00 B │ MergeTree │ 1425397 │ 0.00 B │ 0.00 B │ nan │
│ system │ query_log │ 110 │ 2022-10-17 17:45:46 │ 39.87 KiB │ 24.00 B │ MergeTree │ 40827 │ 0.00 B │ 0.00 B │ nan │
└────────────────┴─────────────────────────┴────────────┴─────────────────────┴────────────┴───────────────────┴───────────┴──────────────┴─────────────────┴───────────────────┴──────────────────────┘
This is commendable and a result of column compression done by both databases.
Results
Without much ado, here is the time taken by both databases on the 13 queries in the Star Schema Benchmark.
| BigQuery (s) | ClickHouse (s) | DuckDB (s) | |
| Q1.1 | 1.315 | 5.991 | 52.67 |
| Q1.2 | 1.251 | 0.460 | 50.83 |
| Q1.3 | 1.637 | 0.108 | 47.87 |
| Q2.1 | 2.507 | 33.767 | 70.74 |
| Q2.2 | 2.386 | 9.579 | 57.43 |
| Q2.3 | 1.728 | 8.482 | 54.77 |
| Q3.1 | 2.367 | 15.779 | 63.03 |
| Q3.2 | 3.42 | 13.690 | 64.79 |
| Q3.3 | 4.056 | 9.466 | 52.34 |
| Q3.4 | 1.777 | 0.158 | 50.22 |
| Q4.1 | 2.479 | 25.276 | 74.31 |
| Q4.2 | 2.094 | 4.945 | 86.21 |
| Q4.3 | 2.213 | 3.874 | 79.24 |
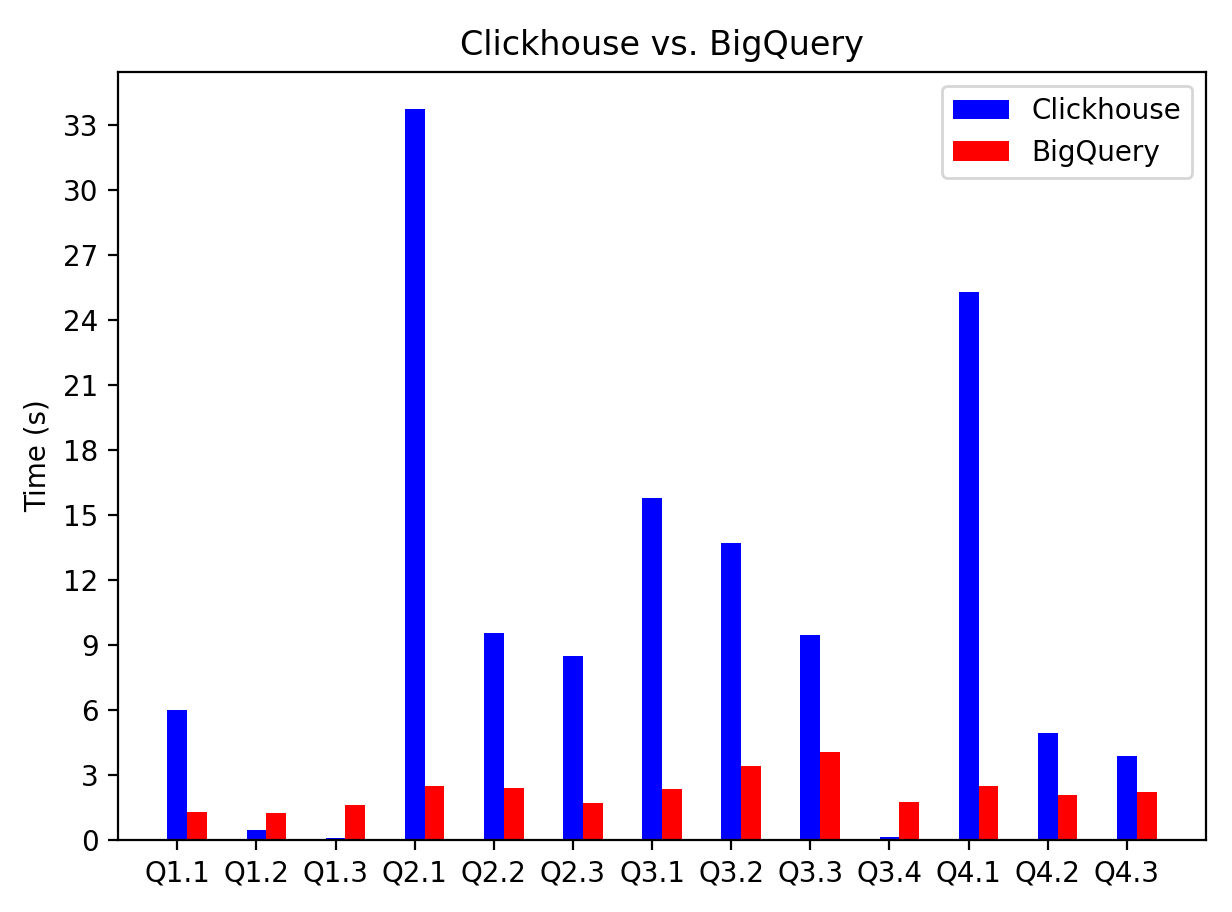
We can easily see BigQuery is faster. I suspect this is because Clickhouse was run on a single node (8 vCPUs and 32 GB RAM). E.g., when the job details of Q2.1 were inspected,
SELECT
sum(LO_REVENUE) as revenue,
extract(Year from LO_ORDERDATE) AS year,
P_BRAND
FROM lineorder_flat
WHERE P_CATEGORY = "MFGR#12" AND S_REGION = "AMERICA"
GROUP BY
year,
P_BRAND
ORDER BY
year,
P_BRAND
BiqQuery shows 3 stages:
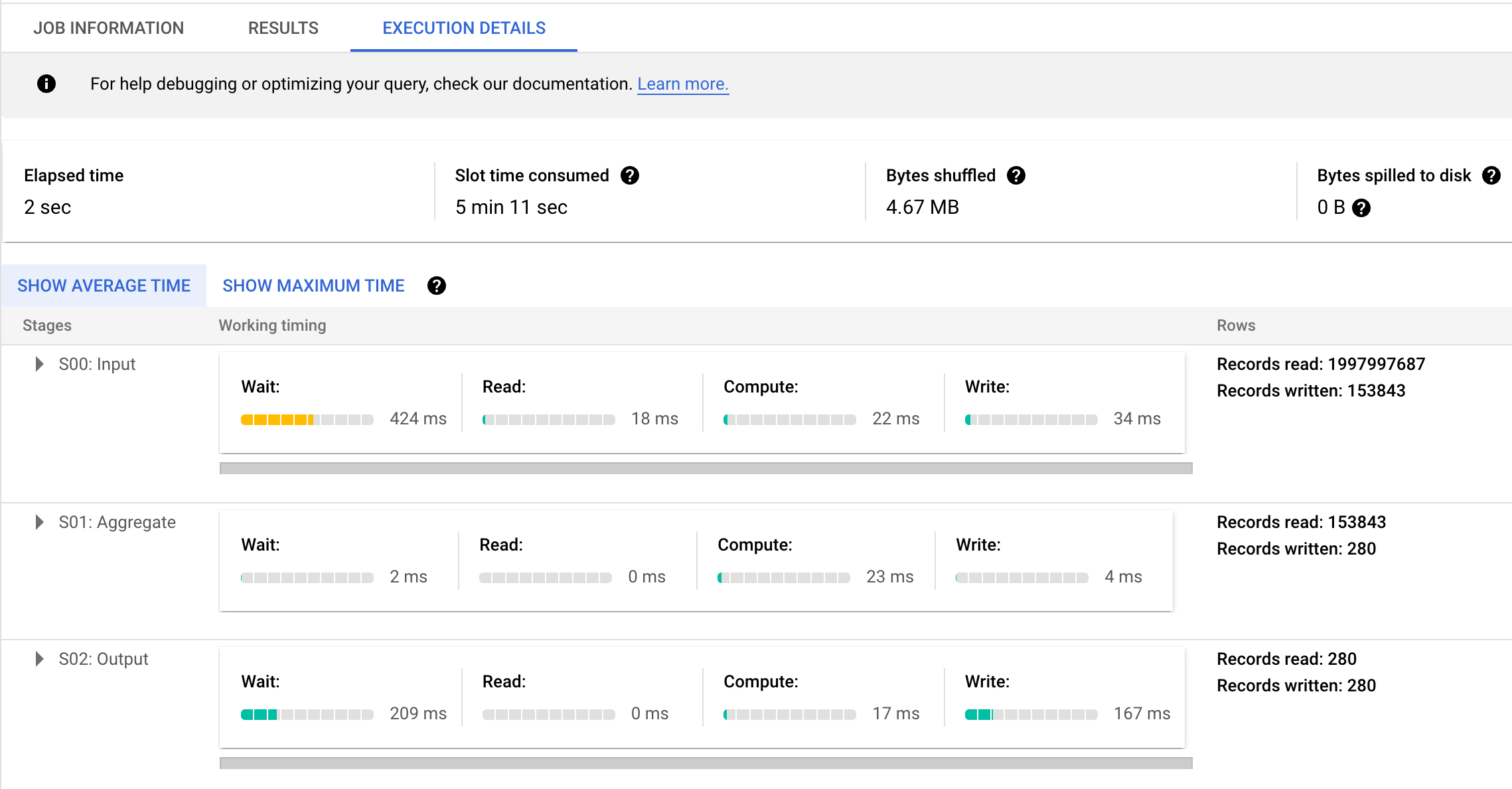
and drilling further, it was seen there were 3847 parallel inputs in Stage 1 (S00). Both BigQuery and Clickhouse did a full table scan but BigQuery massively parallelized the work across 3847 workers (slots). Its hard to beat this. The total slot milliseconds of BigQuery came in at 311,716 ms.
It is also interesting to compare the execution details of Q1.3 where Clickhouse beats BigQuery (0.108ms for Clickhouse vs 1.6s for BQ). The query itself is:
SELECT sum(LO_EXTENDEDPRICE * LO_DISCOUNT) AS revenue
FROM lineorder_flat
WHERE (toISOWeek(LO_ORDERDATE) = 6) AND (toYear(LO_ORDERDATE) = 1994) AND ((LO_DISCOUNT >= 5) AND (LO_DISCOUNT <= 7)) AND ((LO_QUANTITY >= 26) AND (LO_QUANTITY <= 35))
Clickhouse was blazingly fast on this query and was seen to process 5.89 million rows whereas BigQuery for some reason processed 303,097,581 rows (which was also equal to the total number of rows in the partition containing the year 1994 and 50 times more than 5.89M; recall there are 52 weeks in a year) across 587 workers.
It is instructive to compare the # of rows processed between the two. This is shown by following graph:
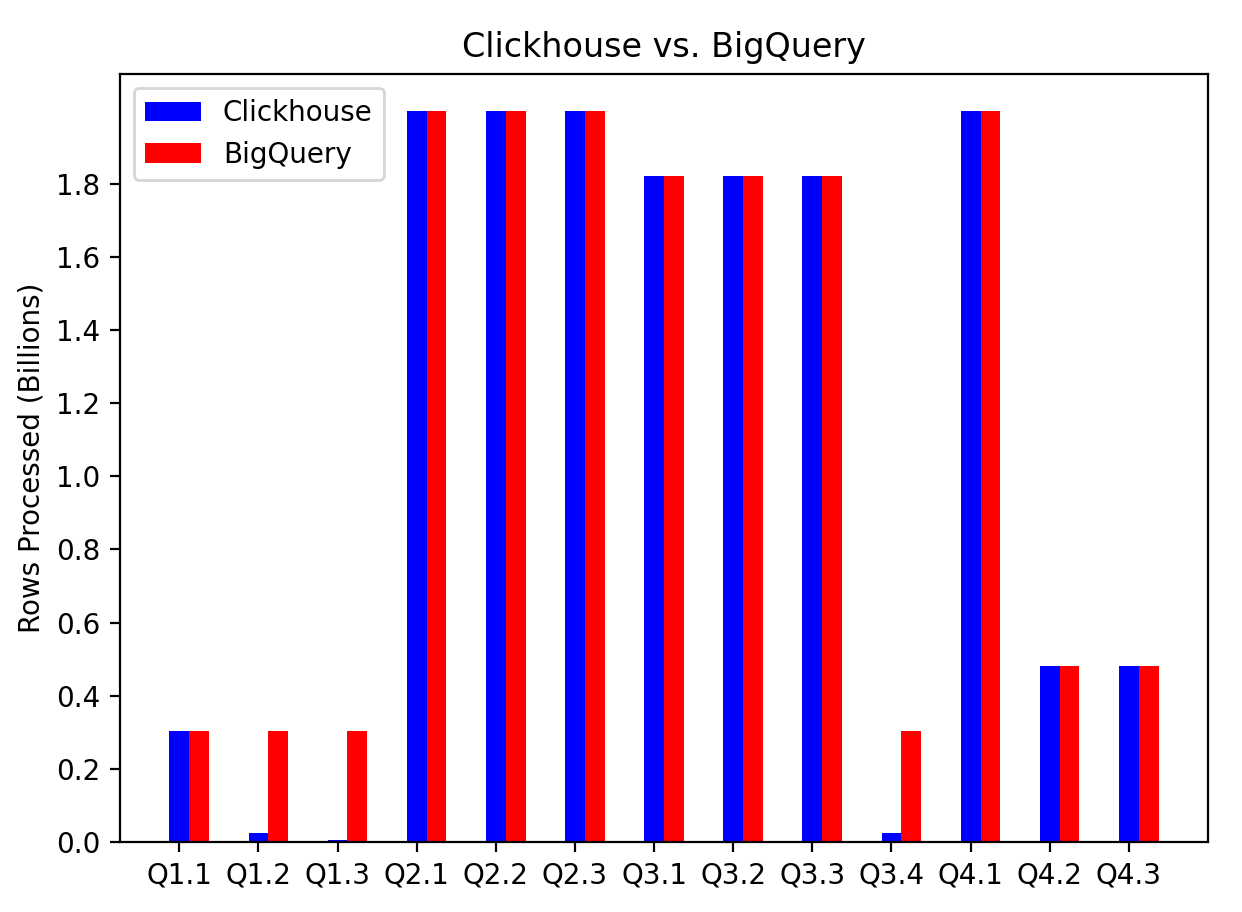
It can be seen that the cases when Clickhouse is faster (Q1.2, Q1.3 and Q 3.4) can be attributed to scanning through a much smaller subset of the data. In all these cases the query had a where filter which was more fine-grained than just the year. E.g., in Q1.2 has predicate on month, Q1.3 has predicate on ISO week and Q3.4 has predicate on month again.
Conclusion
This brings us to the conclusion. Although we can see that BigQuery is faster, this post is not meant to endorse BigQuery over Clickhouse. Clickhouse was run on a single node – who knows what the numbers would be if its run on a cluster? But the question is how do you decide how big of a cluster to provision? And once you have provisioned the cluster, its static – you can’t resize it – or maybe you can but it won’t be trivial and not something you would do often. This is where BigQuery really shines and is the most important lesson learned. It dynamically auto-scales the compute in response to the query. It might not do as clever of indexing (refer [2] and [3]) but its hard to beat the massive parallelization it does behind the scenes. It can pretty much brute-force any query and still come on top. The motivation to use CH would be when you want to reduce costs and do things in-house.
Appendix: DuckDB Notes
In case of DuckDB tests were run on same machine as CH e2-standard-8 with 8 vCPU and 32GB RAM. I found that DuckDB did not take advantage of multiple CPUs while running the queries. The CPU usage was between 100-200% with more towards the lower end. Also below are sizes to give an idea:
| Object | Size (GB) |
| lineorder.lbl | 239 |
| DuckDB table after loading lineorder.tbl but before denormalization (joins with other tables) | 60 |
| DuckDB table after lineorder has been denormalized to lineorder_flat | 259 |
In addition denormalization step took 3073s. Other thing to add as a note is that DuckDB uses single quotes instead of double quotes in WHERE clause. So WHERE P_CATEGORY = "MFGR#12" AND S_REGION = "AMERICA" becomes WHERE P_CATEGORY = 'MFGR#12' AND S_REGION = 'AMERICA'.