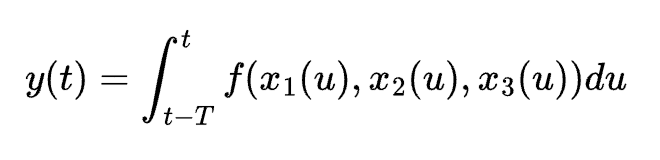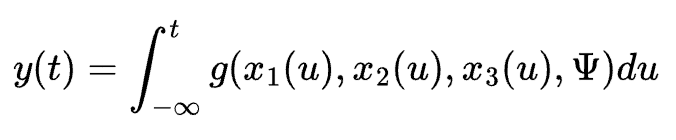Summary:
- there are two types of credentials: user credentials (associated with a person) and service credentials (not associated with any person)
- Service credentials are stored in a JSON keyfile and can be downloaded from GCP console
- User credentials are obtained by running
gcloud auth login and stored in a SQLite database ~/.config/gcloud/credentials.db
- It is also possible to generate user credentials by running
gcloud auth application-default login. These are stored in ~/.config/gcloud/application_default_credentials.json and known as ADC (application default credentials)
- All in-built Command line tools that ship with Google Cloud SDK will attempt to use ADC if they can. You can override this by setting the
GOOGLE_APPLICATION_CREDENTIALS environment variable or the --account flag.
- If your users are authenticating using SA, you lose the auditability of who is actually doing what unless that is tracked somewhere else. E.g., someone deleted a database. If they used a SA, you can’t tell who did it – unless its tracked somewhere else.
- For applications that are deployed in managed infrastructure such as Cloud Run, always run them under a SA that you set using the
--service-account flag.
There are many ways you can authenticate your application against GCP. Applications that run in managed GCP services such as Cloud Run should run under a service account’s identity. They will automatically authenticate themselves against GCP with the permissions and privileges associated with the service account. You don’t have to write any authentication code in your app. You should create a service account and assign it appropriate permissions. Then when you deploy the application, use the --service-account flag to set the SA:
--service-account=SERVICE_ACCOUNT Service account associated with the revision of the service. The service account represents the identity of the running revision, and determines what permissions the revision has. For the managed platform, this is the email address of an IAM service account. For the Kubernetes-based platforms (gke, kubernetes), this is the name of a Kubernetes service account in the same namespace as the service. If not provided, the revision will use the default service account of the project, or default Kubernetes namespace service account respectively.
In rest of this post, I focus on how applications that are NOT deployed in GCP should authenticate themselves against GCP. Think of a command-line tool you develop e.g., I developed a tool that copies data from on-prem database to BigQuery. This tool is not deployed in GCP. You run it from a on-prem VM. There are actually many ways the application could authenticate against GCP.
First of all, you need to decide if you want to authenticate as the user who runs the tool or as a service account (SA). Authenticating with User credentials will allow you to audit who was the person that ran the tool. With SA credentials you lose that auditability – unless its tracked somewhere else e.g., the app uses a SA proxy to authenticate against GCP but you keep track of who is running the app – perhaps user logs in to a portal or website and then they click on a button which runs the tool under the covers for them on their behalf (that is what a proxy means). This is a perfectly acceptable and well-designed system.
SA authentication is always done through a keyfile. It is a JSON file. You should download the keyfile from GCP console and your application should have access to it. If you open a SA keyfile, you will see following line in it:
"type": "service_account"
User authentication can be done through a keyfile or dynamically (OAuth2) where user is presented with a screen and asked to sign in on Google’s website using their Google ID and password. Here I focus on authenticating using a keyfile. A user should NEVER share their keyfile with anyone as it represents their identity. If you share your keyfile, you are willingly giving away your identity to someone else. So you would NOT use a keyfile that contains your user credentials on a shared computer (more accurately you could but it should be accessible only to you). But its okay to use a keyfile that contains your user credentials on your private PC.
To generate this keyfile, run following command:
gcloud auth application-default login
You will be prompted to enter your username (Google account email) and password. Then you will be presented with a consent screen and if you provide consent, your keyfile will get saved on the system under ~/.config/gcloud/application_default_credentials.json. All the built-in GCP commands such as gcloud, bq etc. will attempt to use ADC if you do not override that by setting GOOGLE_APPLICATION_CREDENTIALS or the --account flag. From the docs:
After running gcloud auth commands, you can run other commands with --account=ACCOUNT to authenticate the command with the credentials of the specified account.
If you open a keyfile that belongs to a user such as the one above, you will see following line in it:
"type": "authorized_user"
Contrast this to the type we saw for a SA. This is how we can distinguish between user credentials and service account credentials. The Java code to implement this logic would look like:
private static enum CREDENTIAL_TYPE { User, Service };
private static CREDENTIAL_TYPE getCredentialType(String file) throws IOException {
try (FileInputStream fs = new FileInputStream(file)) {
JSONTokener tokener = new JSONTokener(fs);
JSONObject root = new JSONObject(tokener);
String type = root.getString("type").toLowerCase();
if (type.equals("service_account")) {
return CREDENTIAL_TYPE.Service;
} else if (type.equals("authorized_user")) {
return CREDENTIAL_TYPE.User;
} else {
throw new IllegalStateException("don't know how to classify " + type + " account");
}
}
}
You can also acquire user-credentials by running:
The credentials acquired in this way are stored in a SQLite database which can be found at ~/.config/gcloud/credentials.db. The --account flag that comes with gcloud reads credentials from this file.
Let us now see how your application can authenticate against GCP similar to how tools like gcloud do. For starters, you can use the built-in authentication that comes with GCP client libraries. You don’t have to do anything special in your code if you use the built-in authentication. E.g., you can just call:
BigQueryOptions.newBuilder()
.setProjectId(projectId)
.build()
.getService();
What it does: It will attempt to authenticate using ADC unless the GOOGLE_APPLICATION_CREDENTIALS environment variable is set. I am very confident but not 100% sure of it so take it with a grain of salt. In fact, that’s why I like to explicitly specify the credentials file in my code so there is no confusion about what credentials are being used for authentication. One you have the path to a keyfile, you can build the authentication credentials as follows:
public static GoogleCredentials createCredentials(String path) throws IOException {
path = new StringSubstitutor(System.getenv()).replace(path);
logger.info("initializing GCP credentials from {}", path);
CREDENTIAL_TYPE type = getCredentialType(path);
try (FileInputStream fs = new FileInputStream(new File(path))) {
if (type == CREDENTIAL_TYPE.Service) {
return ServiceAccountCredentials.fromStream(fs);
} else if (type == CREDENTIAL_TYPE.User) {
return UserCredentials.fromStream(fs);
} else {
throw new IllegalStateException("unable to create GCP credentials");
}
}
}
and use them in call to setCredentials on BigQueryOptions.The
path = new StringSubstitutor(System.getenv()).replace(path);
takes care of handling a path that has environment variables like $HOME in it. E.g., the path could be ${HOME}/path/to/something. Refer this for more.