
from https://www.uber.com/blog/presto
While batch and ETL jobs run on Hive and Spark, near real-time interactive queries run on Presto.
this is a sentiment I have seen at other places as well – use presto for adhoc, near real-time analytics. My question is:
what is the harm in using Presto for ETL and batch jobs if it can run them faster?
surely if its capable of running adhoc queries then it can also run fixed queries and if it can run adhoc queries in real-time, it should be able to run fixed queries in real-time as well.
My understanding:
- Use Hive when you want to use SQL for all data processing. If you do use Hive, use Tez as the execution engine instead of MR (mapreduce).
- use Spark when you want to mix SQL with a programming language. It also has a superior architecture compared to Hive. Hive uses MR (mapreduce) by default which is slow and outdated. Spark uses in-memory processing. From wikipedia: Spark and its RDDs were developed in 2012 in response to limitations in the MapReduce cluster computing paradigm, which forces a particular linear dataflow structure on distributed programs
- use Presto when you want to do adhoc and near real-time queries. does it put it in the same club as ClickHouse, SingleStore, AlloyDB, Pinot, Druid etc.?
Why am I asking this here and not on SO? I have tried to ask questions like this on SO but such discussion oriented questions receive a lot of downvotes on SO and are closed. So this time I am saving myself the trouble. I did find a very similar question here. Why don’t I ask it on reddit? I don’t like that site very much and don’t have an account on it and don’t want to create one. Similarly with quora. All these sites benefit at your expense.
from sotagtrends:
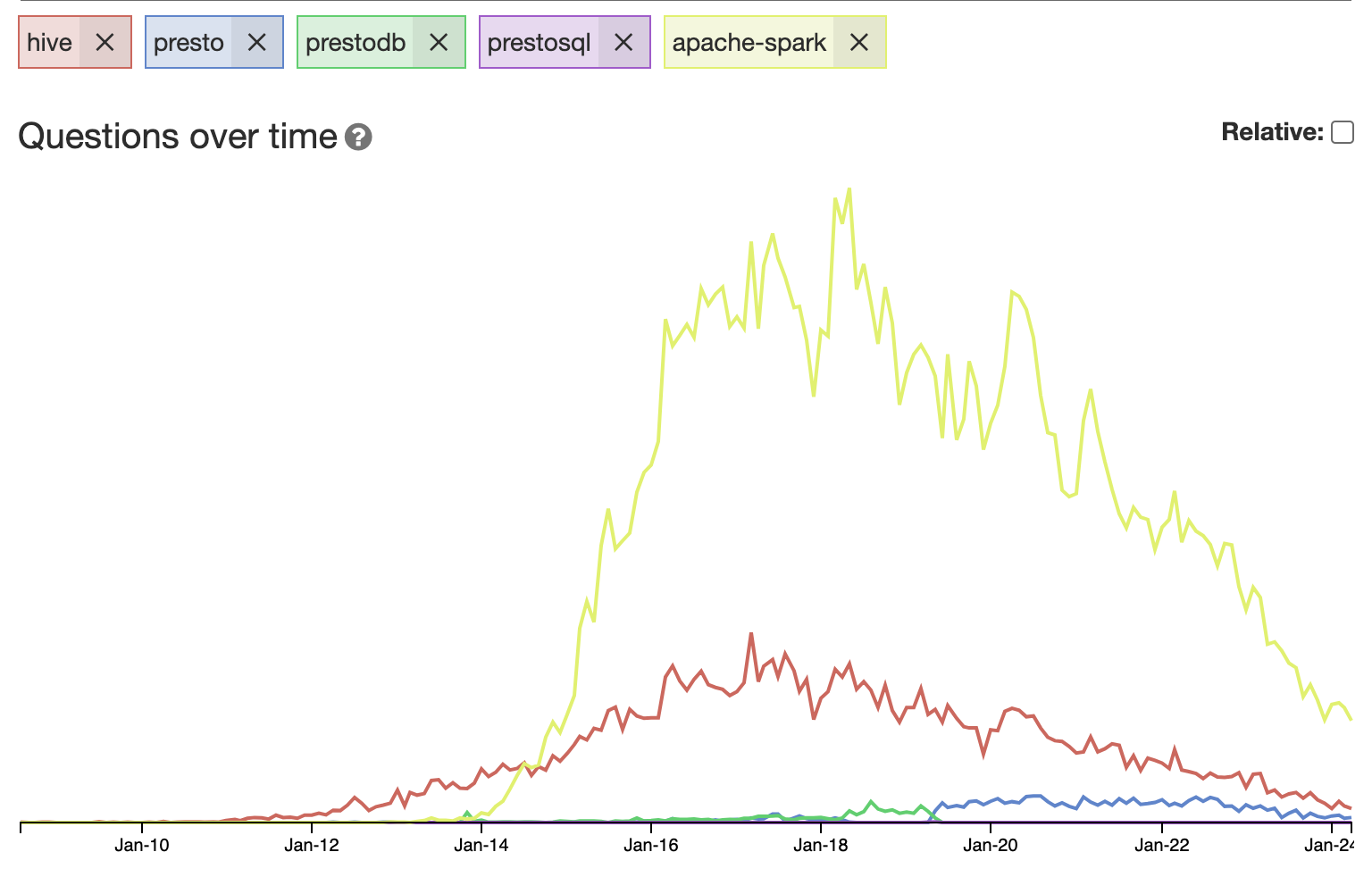
If all these are in decline since 2018 then what’s the next thing that is gaining popularity?
You know what is interesting about all 3? all of them are developed in Java (Spark was/is developed in Scala but Scala and Java are not much different; both run on the JVM and compile to same bytecode). In fact, I started compiling a list of big data and other backend technologies and they use Java quite a lot:
- Apache Pinot
- Druid
- Cassandra
- Lucene
- ElasticSearch
- Neo4J
- Kafka
- Trino
- Presto
- Hadoop
- Hive
- HBase
- Zookeeper
- Flume
- Storm
- Impala
- Spark
- DynamoDB
All these projects are developed in Java and it goes on to show Java’s dominance in the big data and distributed backend landscape. let me know if there are any others I should add to this list.
