
MapDB is a popular persistent key-value store written entirely in Java and Kotlin. It is the top choice amongst SO users for a Java based persistent KV store [1],
its Github repo has 4.8k stars and it comes with minimal dependencies (mainly Guava, Eclipse Collections and net.jpountz.lz4:lz4)
so it definitely has something going for it.
Now lets come to the not-so-rosy facts. AFAICT, you can’t create transactions like you do with MySQL or Postgres. There is only support for a single global transaction. Its mostly developed by just 1 person. He doesn’t answer questions most of the time. I don’t blame him. His business model is to give away MapDB for free and then charge for consulting. He has to monetize somehow. The documentation is not great. More dangerous is the fact that it is not up to date (an euphemistic way of saying its inaccurate). The author made announcements of a v4 in 2017 and after 7 years we have yet to see any code, just empty repos [1]!
In this post I try to unpack what I have learnt about how MapDB works. A MapDB KV store can have two backing implementations:
- HTreeMap implements
ConcurrentMap: this is an IndexTree in the author’s own words and we will see what he means by that. - BTreeMap implements
ConcurrentNavigableMap: this is the B-Tree data structure we know about (I hope).
There is also IndexTreeList (not to be confused with
IndexTreeListJava – this is why I don’t like this library as the code is so hacky with confusing names, part Java, part Kotlin and so on) which is supposed to
provide persistent AbstractList but its not KV store and we do not cover it here.
An HTreeMap is created using [1]:
db.hashMap
which will make a call to HashMapMaker:
class HashMapMaker<K,V>(
protected override val db:DB,
protected override val name:String,
protected val hasValues:Boolean=true,
protected val _storeFactory:(segment:Int)->Store = {i-> db.store}
):Maker<HTreeMap<K,V>>(){
whereas a BTreeMap is created using [1]:
db.treeMap
which will call TreeMapMaker:
class TreeMapMaker<K,V>(
protected override val db:DB,
protected override val name:String,
protected val hasValues:Boolean=true
):Maker<BTreeMap<K,V>>(){
HTreeMap vs. BTreeMap
In my tests, the HTreeMap outperformed the BTreeMap. YMMV depending on the workload and read-write patterns.
Later, I provide some arguments why this is so.
In below, we will delve more into the HTreeMap.
I will try to unpack BTreeMap later if I am able to but basically its a concurrent B-tree implemented according to [1]
HTreeMap takeaways
HTreeMapcombines the hashing of a HashMap with the tree data structure of a TreeMap. Hence the nameHTreeMap.- The data does not need to be rehashed as the
HTreeMapgrows because the capacity of underlying treemap (max # of keys it can contain) is fixed. This requires mapping the potentially infinite universe of keys to a finite set and is the reason for hashing the keys. - The “not need to be rehashed” property is NOT because a treemap is used.
HTreeMapcould have used a fixed size hashtable (array) and keys would not need rehashing as a result. - The reason for using a treemap instead of a hashtable (array) is so that we have a sparse data structure where we allocate space only as necessary. Using an array (hashtable) would have meant allocating space for the entire array even if you stored just a handful of values in the
HTreeMap.
| HashMap | TreeMap | HTreeMap |
|---|---|---|
| keys are hashed | keys are not hashed | keys are hashed |
| uses array (the hashtable) | uses a tree | uses a tree |
| uses variable height red-black tree | uses a fixed height N-ary tree | |
| size is unbounded | size is bounded |
The HTreeMap is an array of MutableLongLongMaps [1]:
val indexTrees: Array<MutableLongLongMap>
MutableLongLongMap is a Map where both the
key and value are long. Note that MutableLongLongMap
is an interface. In reality, a sublass of MutableLongLongMap is stored in the array. This subclass is
the IndexTreeLongLongMap and when you read index tree in MapDB documentation, it is referring to this class.
The function that seems to do most of the heavy work when a KV pair is inserted into a HTreeMap is this:
protected fun putprotected(hash:Int, key:K, value:V, triggered:Boolean):V?{
Understand this function and you understand how HTreeMap works. There is a documentation page on HTreeMap. It says:
HTreeMap is a segmented Hash Tree. Unlike other HashMaps it does not use fixed size Hash Table, and does not rehash all data when Hash Table grows. HTreeMap uses auto-expanding Index Tree, so it never needs resize. It also occupies less space, since empty hash slots do not consume any space. On the other hand, the tree structure requires more seeks and is slower on access. Its performance degrades with size TODO at what scale?.
The hash table equivalent that powers an HTreeMap is IndexTreeLongLongMap.
It is a persistent KV store implemented as a tree map not as a hash table. A hash table has to rehash all the keys
when the size of the underlying array changes (this is because the result of the hash function has to be “modded” (a mod b) by the array size to map it to an element in the array) but
IndexTreeLongLongMap does not need to rehash the keys which is a win.
How come it does not need to rehash? Because the capacity of the tree (max # of nodes it can contain) is fixed.
The auto-expanding feature will be understood when we cover internals of IndexTreeLongLongMap. We will revisit this paragraph later when we have fully unpacked IndexTreeLongLongMap.
Concurrency is implemented by using multiple segments, each with separate read-write lock. Each concurrent segment is independent, it has its own Size Counter, iterators and Expiration Queues. Number of segments is configurable. Too small number will cause congestion on concurrent updates, too large will increase memory overhead.
The number of segments is the size of the indexTrees array. It is a fixed-size array not dynamic. The size of the array is controlled by the concShift variable
which is the power of 2 to be raised to give the array size. We see that happening here:
indexTrees: Array<MutableLongLongMap> = Array(1.shl(concShift), { i->IndexTreeLongLongMap.make(stores[i], levels=levels, dirShift = dirShift)}),
1.shl(concShift) is how you raise 2 to a power in Kotlin.
HTreeMap uses Index Tree instead of growing Object[] for its Hash Table. Index Tree is sparse array like structure, which uses tree hierarchy of arrays. It is sparse, so unused entries do not occupy any space. It does not do rehashing (copy all entries to bigger array), but also it can not grow beyond its initial capacity.
The Object[] in above is reference to how an in-memory hash table is implemented in Eclipse Collections for example. It uses an object array underneath [1]. HTreeMap on the other hand is powered by a
persistent TreeMap like data structure.
This difference is key in understanding HTreeMap. It does not use a backing array (we shall see why later on) but instead maintains the keys in a tree (called as the index tree in
documentation).
HTreeMap layout is controlled by layout function. It takes three parameters:
concurrency, number of segments. Default value is 8, it always rounds-up to power of two.
we covered this earlier. here he is refering to the concShift variable.
The default value is 3 [1] which gives 2**3=8 segments.
maximal node size of Index Tree Dir Node. Default value is 16, it always rounds-up to power of two. Maximal value is 128 entries.
This is reference to HTREEMAP_DIR_SHIFT which is equal to 7 in latest code.
I think the node size is given by 2**7 and is 128 now by default. Node size is simply the # of children of a node.
number of Levels in Index Tree, default value is 4
this most-likely refers to HTREEMAP_LEVELS.
Maximal Hash Table Size is calculated as: segment * node size ^ level count. The default maximal Hash Table Size is 8*16^4= 0.5 million entries. TODO too low?
This is indeed too low. But if we use the latest values in the code, we get 8*128^4=2^31=2,147,483,648 or 2 billion. This is likely enough.
The take-away here is that there is a pre-defined upper bound on the # of KV pairs that you can store in a HTreeMap.
Hopefully, we trust that the actual storage consumed is a function of # of elements in the HTreeMap, not the upper bound. That would be catastrophic.
Note that node size ^ level count formula is approximate. Given a tree with L levels and N children per node (which is what an IndexTreeLongLongMap boils down to), the total number of nodes is given by:
S = N^0 + N^1 + N^2 + ... + N^L
= (N^(L+1) - 1) / (N - 1)
With N=128 and L=4 this gives S=270,549,121. N^L is equal to the # of leaf-nodes in the tree and the max # of keys the tree can accommodate as we shall see.
The function that converts an element’s index to position in the tree at given level is given by [1]:
protected static int treePos(int dirShift, int level, long index) {
int shift = dirShift*level;
return (int) ((index >>> shift) & ((1<<dirShift)-1));
}
I am not going to try to make sense out of it but try if you can.
We covered a lot but we still don’t know what IndexTreeLongLongMap stores. As I understand it, it stores a mapping of the hash(key) to the record id
abbreviated as recid. Think of recid as pointer to where the record is located in a slotted page structure.
Once you have the recid, looking up a record in the data file by its recid is an O(1) operation.
My guess is that StoreDirect class is an implementation of this slotted page structure or at least
the slotted page structure is a good mental model of StoreDirect.
This is where my understanding and grasp of MapDB breaks down and not really sure what’s going on. The slotted page structure
is just how data is laid out on disk and independent of B-tree data structure. Both the HTreeMap and BTreeMap use StoreDirect to store records (the actual data).
The difference between the two is how they determine the recid needed to lookup a record. In case of BTreeMap it uses a
B-link tree which is basically a concurrent version of B+ tree, whereas HTreeMap is using a hash tree map provided
by IndexTreeLongLongMap. IndexTreeLongLongMap implements org.eclipse.collections.api.map.primitive.MutableLongLongMap.
Note BTreeMap does not use IndexTreeLongLongMap.
Understanding IndexTreeLongLongMap
Let’s first do a recap: HTreeMap works by storing key-value pairs (records) in a data file (an instance of StoreDirect class). To lookup a record by its id (an O(1) operation – the record id is simply the record’s offset in the file), it
maintains the mapping of hash(key) -> recid in an IndexTreeLongLongMap. Why does it not maintain a mapping of key -> recid instead? we will see.
Consider following questions:
- What data is stored in the nodes of this tree?
- Is there any well-known data structure that
IndexTreeLongLongMap.ktmaps to? - How do you manage that the tree only takes up space equal to actual elements in the tree not the upper fixed bound
N^L?
As I understand:
IndexTreeLongLongMapstores the mapping fromhash(key)to the record idrecid. Think ofrecidas offset or pointer to data corresponding to thekeyin persistent storage. This is the key information we need to lookup a key-value pair and implement a HashMap.IndexTreeLongLongMapcan be thought of as a persistentTreeMapwith a large fanout (it is not a binary tree) whose capacity (the maximum # of elements it can contain) is fixed at time of creation. The keys and values are longs. Because the universe of keys is known in advance, we do not have to use red-black trees as in theTreeMapthat comes with JCF. The implementation is much simpler.- By allocating nodes only as necessary. This makes it a sparse tree and this is what he means by auto-expanding. If we had used an array, we would have to allocate space for the entire array at once at time of creation (equal to the capacity of the
IndexTreeLongLongMapwhich can be quite large).
Let’s illustrate with real-world example. MapDB hash function hash(key) produces a 32 bit signed positive integer in the range 0-2,147,483,648 (upper bound is exclusive).
This integer becomes the key of the IndexTreeLongLongMap. In subsequent when we use the term key it shall refer to this integer and not the key in hash(key).
We divide this range across 8 IndexTreeLongLongMap (the segments in MapDB – he does this for better performance; its a way of partitioning the data).
This gives us following ranges (upper bounds are exclusive):
0 - 268,435,456
268,435,456 - 536,870,912
536,870,912 - 805,306,368
805,306,368 - 1,073,741,824
1,073,741,824 - 1,342,177,280
1,342,177,280 - 1,610,612,736
1,610,612,736 - 1,879,048,192
1,879,048,192 - 2,147,483,648
Let’s see how to index the range 0 - 268,435,456. Other ranges are indexed in much the same way.
With a branching factor of N=128 (also known as order), the root node (level 0) of the tree will have following key separators in it (given by dividing 268,435,456 into 128 buckets) much like a B+ tree:
2,097,152
4,194,304
...
In your mind or on a piece of paper draw a B+tree node with above keys in it. Do it! Now there will be 128 child pointers emerging from the root node giving the next level of the tree.
The 0 - 2,097,152 range is divided into 128 buckets in level 1 (I have not drawn diagrams but try to visualize the tree structure by drawing on paper yourself):
16,384
32,768
...
The 0 - 16,384 range is divided into 128 buckets in level 2:
0-128
128-256
...
After this we will get to the leaf level (level 3) which will have pointers to data records (the recid). Total levels = 4.
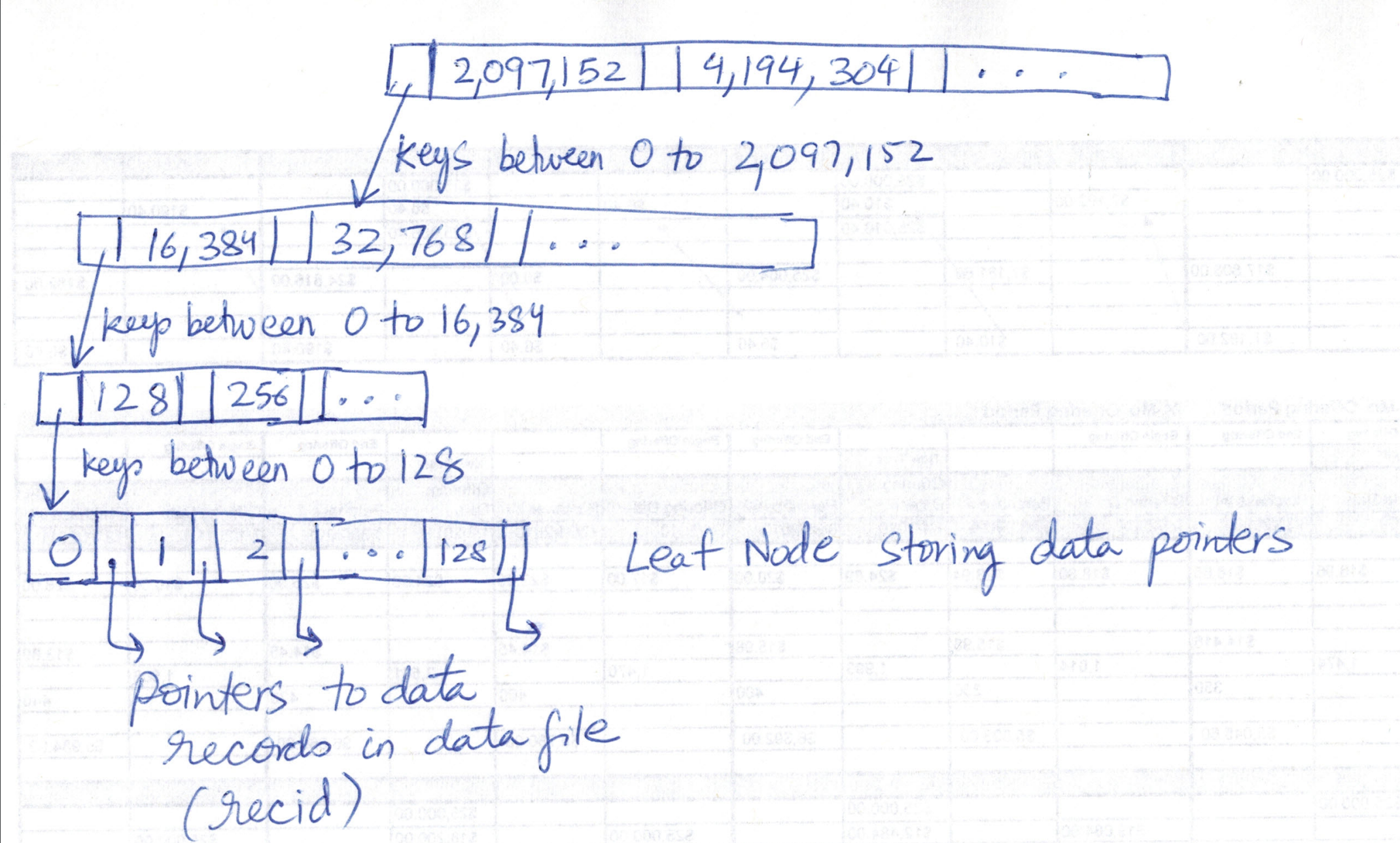
To search for a key, we follow usual search rules in a tree. We start with node and select appropriate child node. If child node pointer is null, key does not exist. To put a KV pair into this tree, we create node(s) as necessary when needed. This is what makes it a sparse tree and this is what auto-expanding refers to.
The keys in this map are integers and the range is fixed a-priori in advance which gives it the performance advantage over BTreeMap I observed in my tests (esp. on inserts) since
tree nodes no longer need splitting and merging. BTreeMap implements the more general purpose B+ tree where you can store arbitrary keys and size (range of keys) is not fixed in advance.
Key range of a IndexTreeLongLongMap
The name IndexTreeLongLongMap might lead you to think that the range of keys that can be stored in IndexTreeLongLongMap is Long.MIN_VALUE to Long.MAX_VALUE but that is WRONG.
There is a much smaller range of keys a IndexTreeLongLongMap can store. It is given by [0, N^L) (upper bound is exclusive) where N is the branching factor of the underlying B+ tree.
N=2^dirShift. L is number of levels. N^L = 1<<(dirShift*levels). Refer the constructor:
fun make(
store:Store = StoreTrivial(),
rootRecid:Long = store.put(dirEmpty(), dirSer),
dirShift: Int = CC.INDEX_TREE_LONGLONGMAP_DIR_SHIFT,
levels:Int = CC.INDEX_TREE_LONGLONGMAP_LEVELS,
collapseOnRemove: Boolean = true
) = IndexTreeLongLongMap(
store = store,
rootRecid = rootRecid,
dirShift = dirShift,
levels = levels,
collapseOnRemove = collapseOnRemove
)
By default, N=128 and L=4. So the default IndexTreeLongLongMap can only store keys in the range [0, 1<<28) or [0, 268,435,456).
Refer following code where the key is checked to be within eligible range before putting a KV pair into the B+ tree:
if(CC.ASSERT && index<0)
throw new AssertionError();
if(CC.ASSERT && index>>>(level*dirShift)!=0)
throw new AssertionError();
Refer following tests to confirm above assertions [1]:
public class IndexTreeLongLongMapTest {
@Test(expected = java.lang.IllegalArgumentException.class)
public void keyCannotBeNegative() {
var store = new StoreTrivial();
var rootRecId = store.put("hello", Serializer.STRING);
var dirShift = 3;
var levels = 3;
var map = new IndexTreeLongLongMap(store, rootRecId, dirShift, levels, true);
map.put(-1, 0); // cannot insert -ve keys
}
@Test
public void test1() {
var store = new StoreTrivial();
var rootRecId = store.put(IndexTreeListJava.dirEmpty(), IndexTreeListJava.dirSer);
var dirShift = 3;
var levels = 3;
var map = new IndexTreeLongLongMap(store, rootRecId, dirShift, levels, true);
var maxKey = 1 <<(dirShift * levels);
map.put(maxKey - 1, 0);
}
@Test(expected = java.lang.AssertionError.class)
public void test2() {
var store = new StoreTrivial();
var rootRecId = store.put(IndexTreeListJava.dirEmpty(), IndexTreeListJava.dirSer);
var dirShift = 3;
var levels = 3;
var map = new IndexTreeLongLongMap(store, rootRecId, dirShift, levels, true);
var maxKey = 1 <<(dirShift * levels);
map.put(maxKey, 0);
}
}
Re-examine some statements
HTreeMap is a segmented Hash Tree. Unlike other HashMaps it does not use fixed size Hash Table,
in above he has the array data structure in mind that is used to implement a hash table.
and does not rehash all data when Hash Table grows.
the array of a hashtable has to be resized as the load factor grows beyond a threshold.
HTreeMap uses auto-expanding Index Tree, so it never needs resize.
as explained above HTreeMap is using a persistent TreeMap data structure underneath. The tree starts out empty and nodes are added as needed.
It also occupies less space, since empty hash slots do not consume any space.
With an array, the empty slots consume space. Space has to be allocated a-priori (whether in main memory or disk) equal to capacity of the hashmap. This is the key reason for not to use an array and use a map powered by a tree instead.
On the other hand, the tree structure requires more seeks and is slower on access. Its performance degrades with size TODO at what scale?.
Array lookup is O(1). Lookup in TreeMap is O(levels).
Why does HTreeMap not maintain a mapping of key -> recid directly?
Because the universe of keys is infinite. The universe of hash(key) is finite. A requirement for IndexTreeLongLongMap. Does it mean HTreeMap cannot handle collisions?
(two different keys with same hash(key))
Fortunately, it does handle them. The record stored in the data file is an array of all KV pairs with same hash(K). This enables disambiguating keys with same hash(key)
as we will see in the next section.
Note that although the capacity of the IndexTreeLongLongMap is fixed, the size of HTreeMap IIUC can grow beyond that.
The # of elements that can be stored is not bounded by the cardinality of the universe of keys. There is guaranteed to be collisions though when # of elements > capacity of the treemap.
I haven’t been able to verify this though. I tried creating a HTreeMap with lower values of
int HTREEMAP_CONC_SHIFT = 3;
int HTREEMAP_DIR_SHIFT = 7;
int HTREEMAP_LEVELS = 4;
int INDEX_TREE_LONGLONGMAP_DIR_SHIFT = 7;
int INDEX_TREE_LONGLONGMAP_LEVELS = 4;
but these are defined as constants. We need to compile a new version of MapDB where these variables can be changed. It is an exercise I leave for the reader.
Does HTreeMap handle hash collisions?
The answer is yes, it does. Here is a test-case [1]:
public class HTreeMapTests {
class MySerializer extends SerializerString {
@Override
public int hashCode(String s, int seed) {
return 8; // return same hash code no matter the input. this will cause collision.
}
}
private final String dbPath = System.getProperty("java.io.tmpdir");
private final String dbFilename =
java.nio.file.Path.of(dbPath, StringUtils.generate_random_string(8) + ".bin").toString();
private DB db;
private HTreeMap<String, String> hmap;
@Before
public void setup() {
db = DBMaker.fileDB(dbFilename).make();
var sz = new MySerializer();
hmap =
db.hashMap(
"my map",
sz,
sz)
.createOrOpen();
}
@After
public void teardown() throws IOException {
Files.delete(Path.of(dbFilename));
}
@Test
public void isAbleToHandleHashCollision() {
hmap.put("hello", "world");
assertEquals(hmap.get("hello"), "world");
hmap.put("jack", "jill");
assertEquals(hmap.get("jack"), "jill");
assertEquals(hmap.get("hello"), "world");
}
}
and the code that resolves collisions is following [1]:
if (keySerializer.equals(oldKey, key)) {
if (expireGetQueues != null) {
leaf = getprotectedQueues(expireGetQueues, i, leaf, leafRecid, segment, store)
}
return valueUnwrap(segment, leaf[i + 1])
}
This disambiguates keys with same hash code by testing for equality.
Back to BTreeMap
If you are using BTreeMap, be aware of the fine print:
This B-Linked-Tree structure does not support removal well, entry deletion does not collapse tree nodes. Massive deletion causes empty nodes and performance lost. There is workaround in form of compaction process, but it is not implemented yet.
In terms of functionality BTreeMap gives you everything that HTreeMap has to offer and even more (e.g., range queries) since
BTreeMap implements ConcurrentNavigableMap
whereas HTreeMap implements ConcurrentMap.
Transactions
MapDB docs brag that:
It also provides advanced features such as ACID transactions, snapshots, incremental backups and much more.
This is rubbish. There is no I in MapDB and C mostly has to do with FK constraints and the like provided by relational databases (which MapDB is not). That leaves us with A (provided by a single global transaction) and D (persistence).
AFAICT, there is no transaction isolation with this DB (v. 3.0.10) [1].
A DB instance (when opened with transactionEnabled) has associated with it an implicit single global transaction and you cannot create transactions like you do with MySQL or Postgres.
In fact since you cannot create any transactions, the point of transaction isolation does not even arise.
I cannot find any TxMaker in
v3.
In this post dated 2016, author wrote:
TXMaker and concurrent transactions are missing. Will be added latter.
and I have yet to see it more than 8 years later! If I am missing something here, please let me know! (also see this)
Transactions are implemented using a WAL (write-ahead log) to undo and perform
a rollback. You enable transactions by turning on transactionEnable:
DB db = DBMaker
.memoryDB() //static method
.transactionEnable() //configuration option
.make() //opens db
When using a persistent (i.e., off-heap) store, a DB without transactions is implemented using StoreDirect class whereas a DB with transactions uses StoreWAL class.
We see that happening here:
if (_transactionEnable.not() || _readOnly) {
StoreDirect.make(...
} else {...
StoreWAL.make(...
Note that enabling transactions has a cost associated to it. Also do not confuse transactions with concurrency control. Transactions allow us to perform multiple operations on the database as an atomic commit (all or none). They are not a concurrency control mechanism. Tx isolation (the I in ACID) is what gives us concurrency control but MapDB has none [1]. Check out RocksDB if you need Tx isolation [1]. However, be prepared for a much sharper learning curve as it has more bells-and-whistles (that is what enterprise software is about) and is not implemented in Java.
Memory Mapping
Memory mapping is a nifty technique provided by some operating systems like Linux which allows application code to access storage on disk as if it were heap storage (RAM).
The function which makes this possible is the mmap sys call in Linux.
mmap() creates a new mapping in the virtual address space of the calling process. The starting address for the new mapping is specified in addr. The length argument specifies the length of the mapping (which must be greater than 0).
In Java the method that does this magic is java.nio.channels.FileChannel.map:
public abstract MappedByteBuffer map(FileChannel.MapMode mode,
long position,
long size)
throws IOException
and has been in Java since 1.4. Take a look at this code in MapDB:
buffer = raf.getChannel().map(mapMode, 0, maxSize);
Memory mapping is very convenient for an application developer as they can then go about writing application code as if they were working with a large byte buffer in the RAM.
LMDB makes heavy use of this and was probably one of the earliest databases to do so. You can enable it in MapDB as well by turning on fileMmapEnable:
/**
* <p>
* Enables Memory Mapped Files, much faster storage option. However on 32bit JVM this mode could corrupt
* your DB thanks to 4GB memory addressing limit.
* </p><p>
*
* You may experience {@code java.lang.OutOfMemoryError: Map failed} exception on 32bit JVM, if you enable this
* mode.
* </p>
*/
In his blog post, MapDB seems to be going in increasing direction of LMDB.
There is new page based store inspired by LMDB.
from now on focus is on memory mapped files. Memory mapped files in Java are tricky (JVM crash with sparse files, file handles…)
I am not sure if this is a good thing because I also tried benchmarking LMDB against MapDB and LMDB performance was just pathetic (was it due to memory mapping or something else, I do not know).
In this post, the author says:
MapDB uses mmap for file persistence, which I get why data stores would want to do that – let the OS deal with the persistence and abstract the file as memory but I am not a fan of it due to corruption issues and the fact that the storage manager can do a much better job than the OS as to what and when to commit pages. Apart from that, the whole point of building a data store product is to control persistence – why would we outsource that to the OS? MongoDB, when it was first launched, used mmap. Once they acquired wired tiger they got rid of mmap. LevelDB uses mmap and then once Facebook forked it to build Rocksdb the first thing they did was to get rid of mmap.
Looks like RocksDB does use mmap. See this, this and this.
mmap does sound hacky to me but looks like everyone (MapDB, LMDB, RocksDB) is using it. It comes with a danger zone (I said it sounds hacky).
Warning: We are going to spend a long time discussing this (its a post unto itself) so as heads up remainder of this section in the post is about this danger zone and you can skip
if you need to.
A memory mapped file has to be unmapped e.g., using the munmap system call after you are done with it but
note there is no unmap method on java.nio.channels.FileChannel.map
and neither is there any close or dispose method on MappedByteBuffer.
So what gives? Nothing. Its a big bug! As stated here:
Memory mapped files in Java are not unmapped when file closes. Unmapping happens when {@code DirectByteBuffer} is garbage collected. Delay between file close and GC could be very long, possibly even hours. This causes file descriptor to remain open, causing all sort of problems…
and in the documentation of FileChannel.map:
The buffer and the mapping that it represents will remain valid until the buffer itself is garbage-collected.
A mapping, once established, is not dependent upon the file channel that was used to create it. Closing the channel, in particular, has no effect upon the validity of the mapping.
What this means is that closing the db (which closes the file) does not really release all the resources.
You might think that you can unmap the file by calling System.gc() which triggers a garbage collection, but
even if we make a call to System.gc() e.g., when the db is closed, still we are not guaranteed unmapping because as I understand System.gc() only requests the garbage collector to perform garbage collection; we can only hope it actually happens.
Even though Java provides System.gc(), it is unusual to see it being used in any application. Its not something I have seen in any production code.
btw, there is no call to System.gc() in db.close() or its downstream methods
[1, 2].
The way MapDB handles the problem (unmaps memory mapped files) is via
this code:
if (cleanerHackEnabled && buffer != null && (buffer instanceof MappedByteBuffer)) {
ByteBufferVol.unmap((MappedByteBuffer) buffer);
}
Here is ByteBufferVol.unmap:
/**
* Hack to unmap MappedByteBuffer.
* Unmap is necessary on Windows, otherwise file is locked until JVM exits or BB is GCed.
* There is no public JVM API to unmap buffer, so this tries to use SUN proprietary API for unmap.
* Any error is silently ignored (for example SUN API does not exist on Android).
*/
protected static boolean unmap(MappedByteBuffer b){
if (CleanerUtil.UNMAP_SUPPORTED) {
try {
CleanerUtil.freeBuffer((ByteBuffer) b);
return true;
} catch (IOException e) {
LOG.warning("Failed to free the buffer. " + e);
}
} else {
LOG.warning(CleanerUtil.UNMAP_NOT_SUPPORTED_REASON);
}
return false;
}
See this for what CleanerUtil does.
This “fix” is guarded behind a cleanerHackEnabled flag which has to be turned on by calling:
dbMaker.cleanerHackEnable()
which brings me to the anti-climax. read the warning before you turn it on:
Please note that this option closes files, but could cause all sort of problems, including JVM crash.
And now the question: would you turn it on after reading this? Is memory mapping worth taking the risk? There is a risk of file corruption no matter whether the flag is on or off.
People have discussed this issue (how to unmap a memory mapped file) on SO as well [1] and here is official JDK bug opened in 2002 and marked won’t fix in 2023 with the last comment saying the functionality we need is in JEP 454: Foreign Function & Memory API (delivered in JDK 22 which is yet to be released at time of this writing). I haven’t had time to look into it. Quoting from this JEP (reinforcing the issue with Javs’s mmap):
More seriously, the memory which backs a direct byte buffer is deallocated only when the buffer object is garbage collected, which developers cannot control.
Indeed has developed a library to make memory mapping easy in Java.
Check it out here.
It bypasses FileChannel.map and works by utilizing the direct mmap sys call to create a memory mapped file.
In particular, now your Java code will be able to unmap a memory mapped file using MMapBuffer.munmap.
If you have any insights on pros and cons of
FileChannel.map
vs. util-mmap, please let me know. I would be curious to hear that.
What about using a vanilla B+ Tree for persistent key value storage?
Why not cut out all the fat and use a B+ tree directly to implement persistent key-value storage? I tried this as well. For starters, there are not many good libraries I could find for a B+ Tree implementation in Java [1]. This itself was surprising.
Here is the TL;DR:
- davidmoten/bplustree – 33 stars
- btree4j – 194 stars. Tried it. Performance is much worse than Mapdb [1].
- andylamp/BPlusTree – 140 stars. This one is a dud because it truncates the values stored into it:
if(s.length() > conf.getEntrySize()) {
System.out.println("Satellite length can't exceed " +
conf.getEntrySize() + " trimming...");
s = s.substring(0, conf.getEntrySize());
MapDB Best Practices and Lessons
- Sequential inserts in
HTreeMaptake same amount of time as random inserts [1] because the key is anyway hashed (and thus effectively randomized) as seen here - In fact in my tests [1] the
HTreeMapoutperformsBTreeMapeven for sequential inserts. I would have expectedBTreeMapmight be faster at least for sequential inserts based on this (since MySQL primary index is backed by a B+ tree; at least that’s what I think) - Do not try to open same db from multiple threads (or multiple applications) at same time. it will not work. MapDB is not designed for such use-case [1]. we can do this in MySQL or Postgres and is known as opening multiple connections to the db, but not with MapDB.
- You can instead multiplex the
DBinstance across multiple threads but remember there is no Tx isolation (there is only a single global transaction). - You may be used to keeping connections to the db short-lived if you have been programming with MySQL or Postgres. The pattern is that a connection is opened in response to a transaction (such as a sales order on an e-commerce website) and is promptly closed once the transaction has been processed. But in case of MapDB, afaict you might be better off opening the db for lifetime of the application. And as I have covered before, if you are using memory map, closing the db does not release the file handle back to the OS anyway so you are not accomplishing anything anyway. I did some tests in which I opened and closed the db in rapid succession and it crashed the OS not just the program (now that I think about it, the most likely cause was the danger zone with memory mapping), so don’t do it! If it helps to understand, in case of MySQL or Postgres the database itself is open and running forever in a separate process; you open and close connections to it (in fact think of multiple applications connecting to same db). But in case of MapDB there is no distinction between “opening the DB and opening a connection to it”.
- turn on
transactionEnableto protect against data corruption in event of a crash. - MapDB recommends to turn on
fileMmapEnableon 64-bit systems for better performance but read the fine-print and know about the danger zone. Perhaps do a perf test without it. From the standpoint of performance it is generally only worth mapping relatively large files into memory [1]. - turn on
counterEnableif you wantHTreeMapto keep track of its size without having to re-calculate it every time the size is requested. - It is best to think of MapDB not as a database, but a thread-safe collections library backed by persistent storage. Thus, don’t compare it and think of using it in ways like you do MySQL or Postgres. But think of it more like an alternative to JCF (Java Collections Framework) or EC (Eclipse Collections) where the data is backed by persistent storage instead
of main memory which is transient. This is reinforced by the fact that HTreeMap implements
ConcurrentMapand BTreeMap implementsConcurrentNavigableMap.
Try some of the experiments above and let me know if you get same results and what you think of MapDB! If you have used both MapDB and RocksDB, please share your experience!
