
Making notes for my understanding.
Summary
llama.cppcan only be used to do inference. It cannot be used to do training [1].- LLMs have this thing called maximum context size or window (measured in number of tokens). AFAIU, the entire conversation is cannot exceed this size. In case of
llama.cppyou specify this size using then_ctxparameter. However, note carefully that this is not something you can set to arbitrary value. You should always set it equal to the context window of the model you are using [2]. For vicuna it is2048[3]. - If you try to go past the context size, this ugly code kicks in. Per my understanding, it creates a new session that keeps
n_keeptokens from the start of previous session and last(n_ctx - n_keep) / 2tokens of previous session. The new session can go on forn_ctx - n_keep - (n_ctx - n_keep) / 2tokens before being reset again. Since this is a hack and poor man’s way of keeping the conversation going, the conversation will start to lose coherence depending on how good the tokens it got. - The context size has a quadratic impact on model performance [4].
- When the program starts, it does a forward pass on the prompt given to it in the command line arguments

To get the output above I modified the source code like this and inserted printf statements:
print_embd(embd, ctx);
printf("\nDEBUG: running forward pass with n_eval = %d, n_past = %d\n", n_eval, n_past);
if (llama_eval(ctx, &embd[i], n_eval, n_past, params.n_threads)) {
fprintf(stderr, "%s : failed to eval\n", __func__);
return 1;
}
llama_eval is doing the forward pass on the neural network. n_past tracks our position in the context window. It is equal to the length of the conversation so far. After this there is some code in the program that will sample the model outputs and output tokens one by one (this gives the animation in the console where you can see words printed one by one). Here is how it works:
- model generates a token
- this token is printed to console and
n_pastis incremented by 1 - Now this token is fed back to
llama_evalto generate the next token. This is the auto-regressive nature of the model. You can see this in action over here. Note at this stepembdcontains only 1 token in it (the token from step 2) whenllama_evalis called.
The loop above will keep repeating ad-infinitum until the model generates an antiprompt token (it looks like more than 1 antiprompt token can be given to the program) at which point it will exit the loop and hand it over to the user to enter some input. Then, the process will repeat all over. embd will now contain the tokenized user’s input.
So in a nutshell this is how it works AFAIU. Important variables and what they do:
embd_inp: stores tokenized user input.embd: stores the token(s) (token ids really) on which the model runs the forward pass of the NN. It is equal to the user input just before its the model’s turn to generate text. And while the model is generating text, it equals one token at a time (length ofembd= 1 during this phase).last_n_tokensis a ring buffer of size = the context length or window. It starts out with zeros. Items are inserted at back of the buffer and each insert is accompanied by a corresponding pop where the first item in buffer is discarded (thrown out).is_interactingisTruewhile model is waiting for user to input text. It isFalsewhile model is generating text.
A closer look at llama_eval function and resetting the context
llama_eval function is called like this in the code:
llama_eval(ctx, &embd[i], n_eval, n_past, params.n_threads)
it makes a call to:
// evaluate the transformer
//
// - lctx: llama context
// - tokens: new batch of tokens to process
// - n_past: the context size so far
// - n_threads: number of threads to use
// - cgraph_fname: filename of the exported computation graph
//
static bool llama_eval_internal(
this is a long function and I did not study it in detail. I am also not a C++ programmer so its difficult for me to understand C++ code. But anyway this is what I think llama_eval does:
- take
n_evaltokens fromembdstarting at positioni. - run the forward pass (aka inference) on the data in step 1. To run the forward pass, the model also uses its context which is history of entire conversation. This history is presumably stored in an internal buffer (call it
buf) which is of sizen_ctx.n_pastis used to tell the model to takebuf[0:n_past-1]of the buffer as the context. Thectxobject is thus stateful. - Before the function returns, the model also adds all the tokens in step 1 to its context – the
buf– starting at positionn_past.
The code in main.cpp subsequently increments n_past right after the function is called:
n_past += n_eval;
Now let’s take a look at the code that resets the context:
// infinite text generation via context swapping
// if we run out of context:
// - take the n_keep first tokens from the original prompt (via n_past)
// - take half of the last (n_ctx - n_keep) tokens and recompute the logits in batches
if (n_past + (int) embd.size() > n_ctx) {
const int n_left = n_past - params.n_keep;
// always keep the first token - BOS
n_past = std::max(1, params.n_keep);
// insert n_left/2 tokens at the start of embd from last_n_tokens
embd.insert(embd.begin(), last_n_tokens.begin() + n_ctx - n_left/2 - embd.size(), last_n_tokens.end() - embd.size());
By resetting n_past to max(1, params.n_keep), we will mark the portion of the internal buffer buf from n_past to n_ctx - 1 as ineligible. We are effectively deleting the model’s accumulated context (i.e., our conversation history) from n_past to n_ctx - 1. After that we are taking last n_left/2 tokens of the conversation and adding that to embd and let the model run from there. So its as if a brand new conversation was started with these initial conditions.
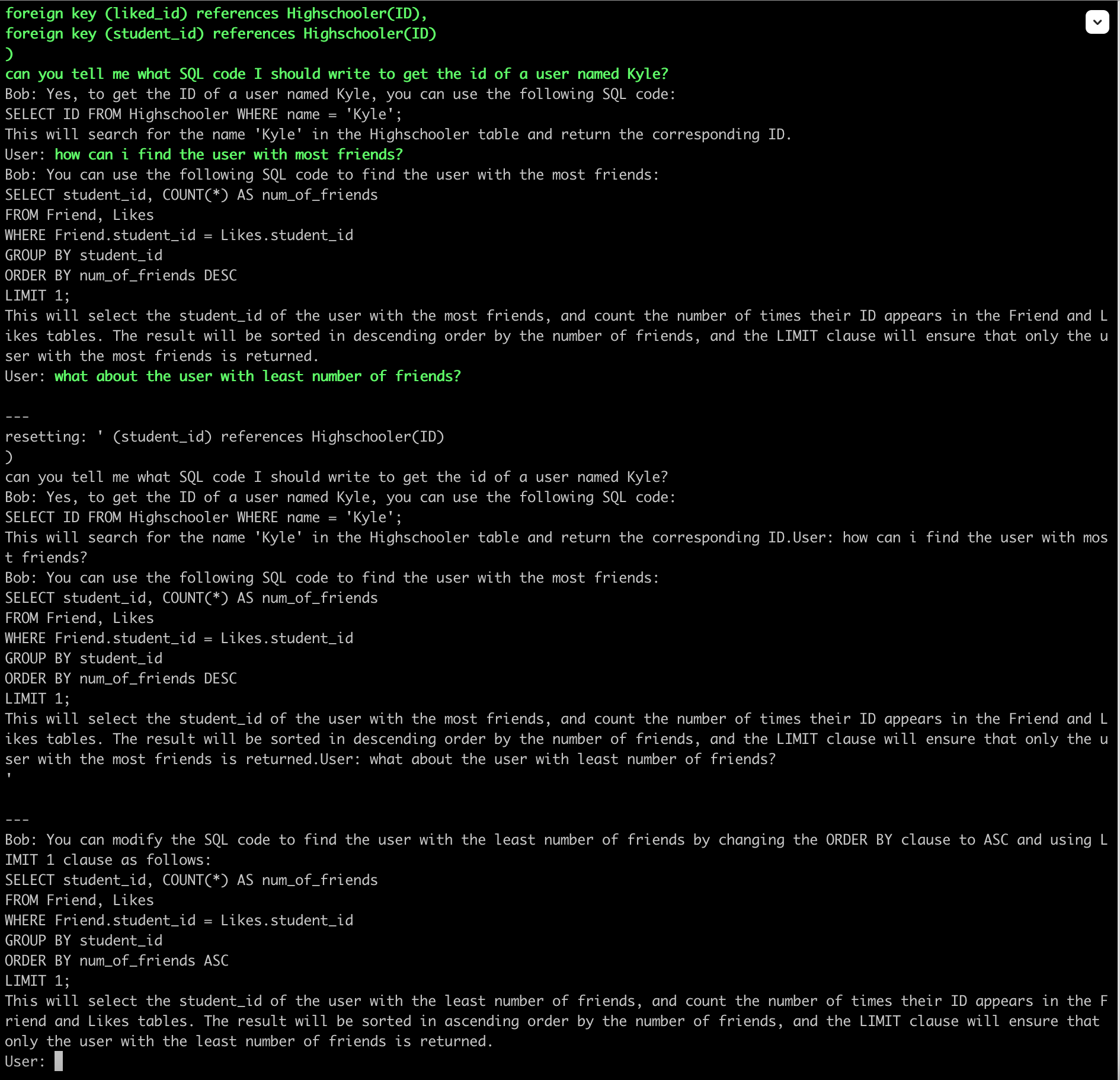
To test this hypothesis, I did following experiment. Below is a screenshot from a conversation when the context gets reset (with n_keep=0 which is the default setting):
compare it to the result when I run a new instance of the program and initializing it with the text when the model got reset in the previous run:
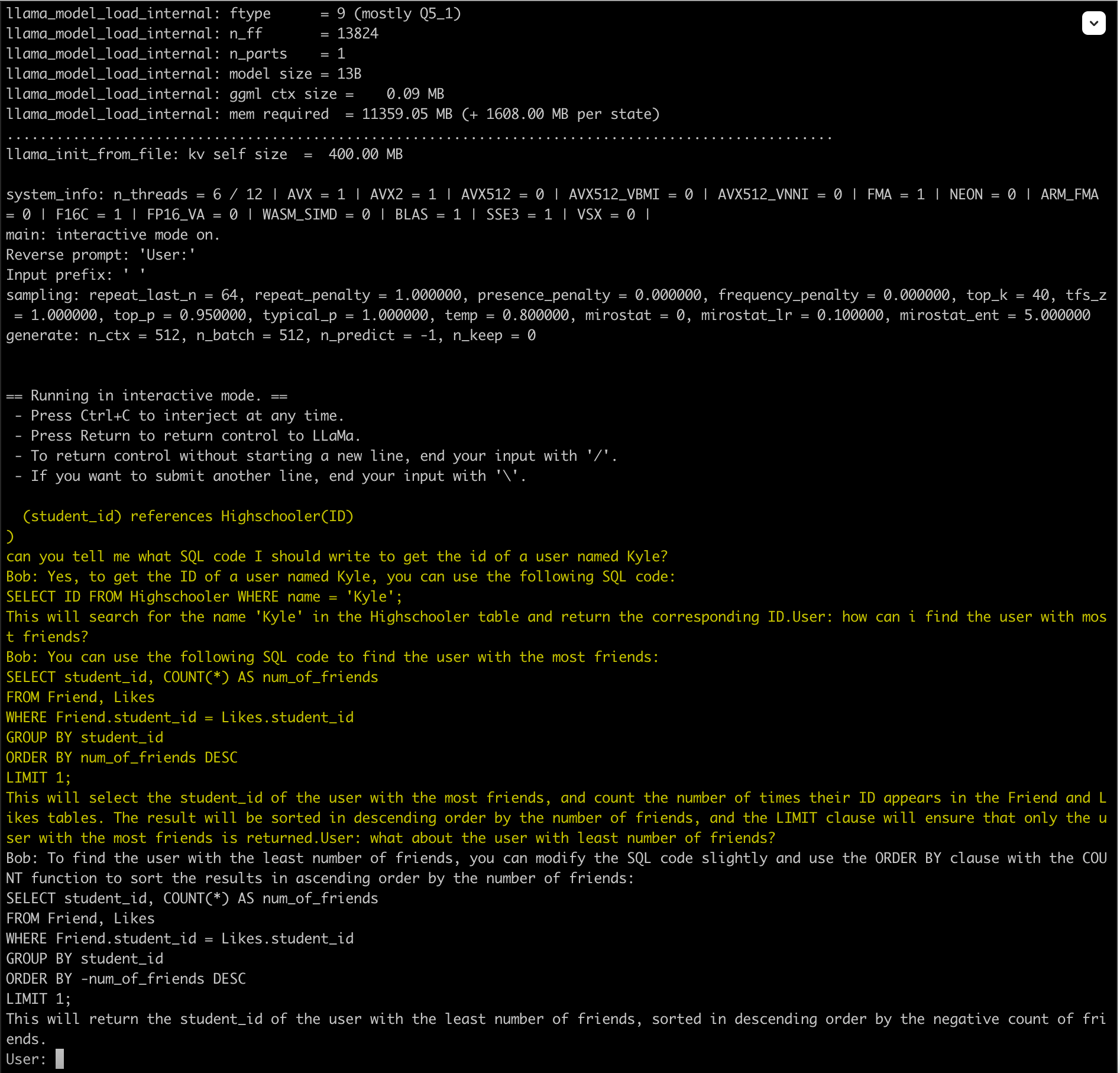
The two outputs are not quite the same. I don’t know if its because of the temperature or something else (maybe my understanding of what happens internally when the context is reset is not fully correct).
What happens if you run the model with a context size that is greater than the context size on which the model was trained?

How I got it to debug
The only way to understand something is to run and step through the code in a debugger. Below are the steps to debug. Also see this:
create debug build (build/debug directory) followed by below steps in that dir:
cmake -DLLAMA_METAL=ON -DCMAKE_BUILD_TYPE=Debug ../..
cmake --build . --config Debug
DCMAKE_BUILD_TYPE=Debug is the crucial setting. without it, it did not work [1].
I got the tip from here.
After that you can cd to directory of the main executable and from there run:
╰─⠠⠵ lldb main
(lldb) target create "main"
Current executable set to '/llm/llama.cpp/build/debug/bin/main' (x86_64).
(lldb) b /llm/llama.cpp/examples/main/main.cpp:54
Breakpoint 1: where = main`main + 57 at main.cpp:54:26, address = 0x0000000100005799
(lldb) run -m /llm/llama.cpp/models/gpt4-x-vicuna-13B.ggmlv3.q5_1.bin --threads 6 -c 2048 --repeat_penalty 1.0 --color -i -r "User:" -f ../../chat-with-bob.txt --in-prefix " " --verbose-prompt
Screenshots:
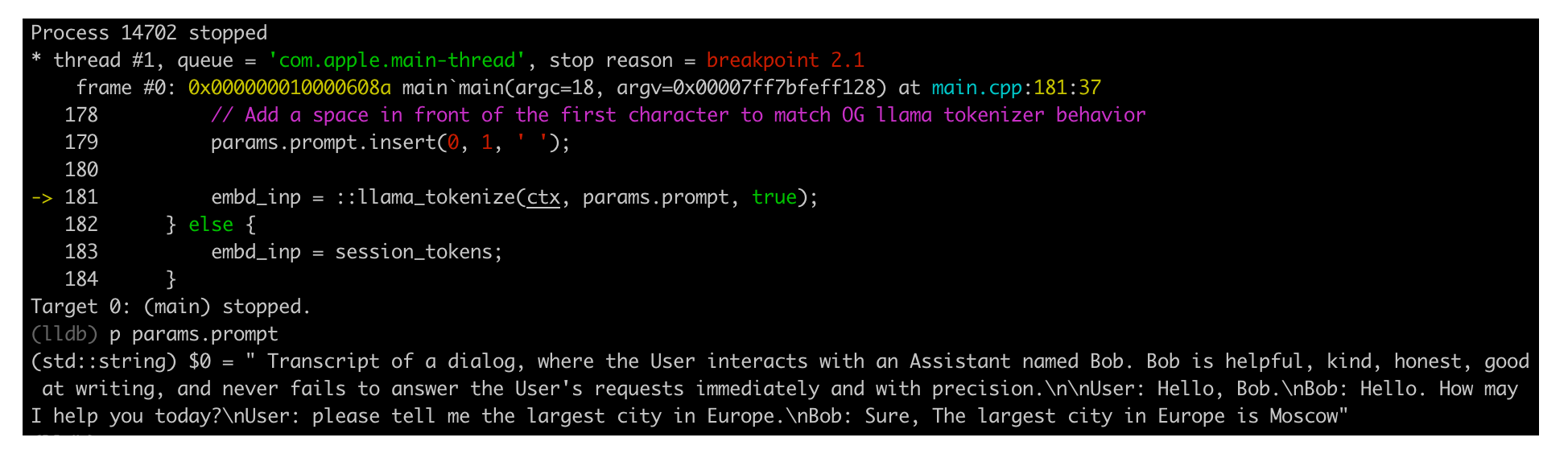
Search for lldb cheat sheet for a cheat sheet. basic lldb commands:
b: set breakpointc: continuep: printexit: exitrun: run the program
