
Wouldn’t it be nice if you could run a private instance of ChatGPT on your company’s private and confidential data? Well, you can do something like it with privateGPT. Although it does not use ChatGPT as that is a proprietary solution, it uses gpt4all which is a freely and publicly available LLM (large language model). Of course, its not as powerful as ChatGPT.
Getting Started
Download code from github. In my case I am synced to commit 60e6bd25eb7e54a6d62ab0a9642c09170c1729e3 which worked for me. Lot of times, you download the code, try to run it and it does not work. Then you have to spend hours and days debugging it.
Steps:
- clone code
- create python virtual environment (
virtualenv venv) - activate python virtual environment (
source venv/bin/activate) - download the model (
wget https://gpt4all.io/models/ggml-gpt4all-j-v1.3-groovy.bin) - install dependencies (
pip3 install -r requirements.txt) - put all your private documents on which you want to run “ChatGPT” inside
source_documents - rename
example.envto.envand edit as necessary - run
python ingest.py
How it works
Running ingest.py is effectively indexing your documents in search lingo.
After that when you run privateGPT.py, in a nutshell, it uses what is known as retriever-reader model which basically works in 2 steps:
- Step 1: A search is performed on the user provided input (query) against your private documents. This is where the index created by
ingest.pyis used. - Step 2: The search results from previous step are used as context. The query + context is given to a LLM (
gpt4all) to answer.
Here you can see it in action. Below is showing the query and context just before its sent to the LLM. The query I typed in was “who was the wife of adolf hitler”. And my private document store just contained one file state_of_the_union.txt which comes with the repo. Below string is sent verbatim to the LLM (gpt4all). So its as if you typed in the following on ChatGPT prompt:
b"Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.\n\nWe don\xe2\x80\x99t know for sure if a burn pit was the cause of his brain cancer, or the diseases of so many of our troops. \n\nBut I\xe2\x80\x99m committed to finding out everything we can. \n\nCommitted to military families like Danielle Robinson from Ohio. \n\nThe widow of Sergeant First Class Heath Robinson. \n\nHe was born a soldier. Army National Guard. Combat medic in Kosovo and Iraq. \n\nStationed near Baghdad, just yards from burn pits the size of football fields.\n\nA former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she\xe2\x80\x99s been nominated, she\xe2\x80\x99s received a broad range of support\xe2\x80\x94from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. \n\nAnd if we are to advance liberty and justice, we need to secure the Border and fix the immigration system.\n\nSix days ago, Russia\xe2\x80\x99s Vladimir Putin sought to shake the foundations of the free world thinking he could make it bend to his menacing ways. But he badly miscalculated. \n\nHe thought he could roll into Ukraine and the world would roll over. Instead he met a wall of strength he never imagined. \n\nHe met the Ukrainian people. \n\nFrom President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world.\n\nOne was stationed at bases and breathing in toxic smoke from \xe2\x80\x9cburn pits\xe2\x80\x9d that incinerated wastes of war\xe2\x80\x94medical and hazard material, jet fuel, and more. \n\nWhen they came home, many of the world\xe2\x80\x99s fittest and best trained warriors were never the same. \n\nHeadaches. Numbness. Dizziness. \n\nA cancer that would put them in a flag-draped coffin. \n\nI know. \n\nOne of those soldiers was my son Major Beau Biden.\n\nQuestion: who was the wife of adolf hitler?\nHelpful Answer:"
below is the call stack just before call to LLM:
File "/github/privateGPT/privateGPT.py", line 76, in
main()
File "/github/privateGPT/privateGPT.py", line 48, in main
res = qa(query)
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/chains/base.py", line 134, in __call__
self._call(inputs, run_manager=run_manager)
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/chains/retrieval_qa/base.py", line 120, in _call
answer = self.combine_documents_chain.run(
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/chains/base.py", line 239, in run
return self(kwargs, callbacks=callbacks)[self.output_keys[0]]
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/chains/base.py", line 134, in __call__
self._call(inputs, run_manager=run_manager)
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/chains/combine_documents/base.py", line 84, in _call
output, extra_return_dict = self.combine_docs(
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/chains/combine_documents/stuff.py", line 87, in combine_docs
return self.llm_chain.predict(callbacks=callbacks, **inputs), {}
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/chains/llm.py", line 213, in predict
return self(kwargs, callbacks=callbacks)[self.output_key]
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/chains/base.py", line 134, in __call__
self._call(inputs, run_manager=run_manager)
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/chains/llm.py", line 69, in _call
response = self.generate([inputs], run_manager=run_manager)
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/chains/llm.py", line 79, in generate
return self.llm.generate_prompt(
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/llms/base.py", line 134, in generate_prompt
return self.generate(prompt_strings, stop=stop, callbacks=callbacks)
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/llms/base.py", line 185, in generate
self._generate(prompts, stop=stop, run_manager=run_manager)
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/llms/base.py", line 411, in _generate
self._call(prompt, stop=stop, run_manager=run_manager)
File "/github/privateGPT/venv/lib/python3.10/site-packages/langchain/llms/gpt4all.py", line 195, in _call
for token in self.client.generate(prompt, **self._default_params()):
File "/github/privateGPT/venv/lib/python3.10/site-packages/gpt4all/gpt4all.py", line 170, in generate
return self.model.generate(prompt, streaming=streaming, **generate_kwargs)
File "/github/privateGPT/venv/lib/python3.10/site-packages/gpt4all/pyllmodel.py", line 220, in generate
prompt,
The call to LLM is this inside /gpt4all/pyllmodel.py:
llmodel.llmodel_prompt(self.model,
prompt,
ResponseCallback(self._prompt_callback),
ResponseCallback(self._response_callback),
RecalculateCallback(self._recalculate_callback),
context)
This will call C/C++ code which will do the HEAVY work. No data is sent to any remote server so you can be sure your private data remains private.
Tips
Running ingest.py for the first time will download some files. Where are they stored?
% ls -al ~/.cache/torch/sentence_transformers/sentence-transformers_all-MiniLM-L6-v2
total 179080
drwxr-xr-x 16 me staff 512 May 25 13:00 .
drwxr-xr-x 3 me staff 96 May 25 13:00 ..
-rw-r--r-- 1 me staff 1175 May 25 13:00 .gitattributes
drwxr-xr-x 3 me staff 96 May 25 13:00 1_Pooling
-rw-r--r-- 1 me staff 10610 May 25 13:00 README.md
-rw-r--r-- 1 me staff 612 May 25 13:00 config.json
-rw-r--r-- 1 me staff 116 May 25 13:00 config_sentence_transformers.json
-rw-r--r-- 1 me staff 39265 May 25 13:00 data_config.json
-rw-r--r-- 1 me staff 349 May 25 13:00 modules.json
-rw-r--r-- 1 me staff 90888945 May 25 13:00 pytorch_model.bin
-rw-r--r-- 1 me staff 53 May 25 13:00 sentence_bert_config.json
-rw-r--r-- 1 me staff 112 May 25 13:00 special_tokens_map.json
-rw-r--r-- 1 me staff 466247 May 25 13:00 tokenizer.json
-rw-r--r-- 1 me staff 350 May 25 13:00 tokenizer_config.json
-rw-r--r-- 1 me staff 13156 May 25 13:00 train_script.py
-rw-r--r-- 1 me staff 231508 May 25 13:00 vocab.txt
More on the internals
PrivateGPT uses langchain and langchain provides two kinds of models:
from langchain.llms import GPT4All, LlamaCpp
...
match model_type:
case "LlamaCpp":
llm = LlamaCpp(model_path=model_path, n_ctx=model_n_ctx, callbacks=callbacks, verbose=False)
case "GPT4All":
llm = GPT4All(model=model_path, n_ctx=model_n_ctx, backend='gptj', callbacks=callbacks, verbose=False)
case _default:
print(f"Model {model_type} not supported!")
exit;
However, note that both these model types use the same llama.cpp library to do the heavy lifting and run the actual inference. This library is written in C/C++ and uses the GGML library for doing the computations – it does not use PyTorch or TensorFlow. AFAIU, the GGML library was originally developed to run inference on the edge (i.e., run on client device on a CPU) but has since added partial GPU support to it.
The way the two model types interop with the C++ library is different and shown in the diagram below:
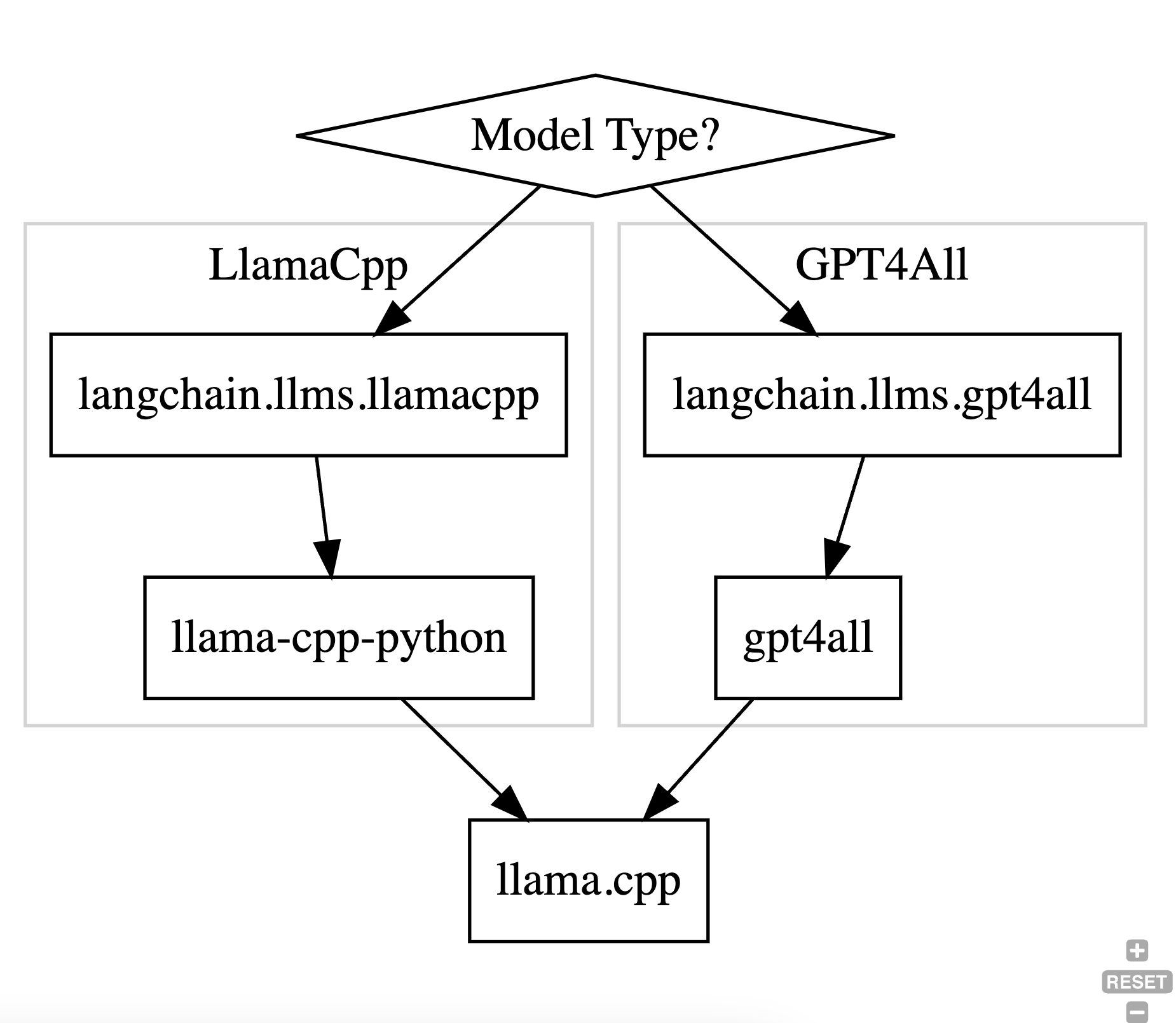
AFAIU, in theory only one branch is needed in the flowchart above. On gpt4all’s website it states:
Currently, there are three different model architectures that are supported:
- GPTJ – Based off of the GPT-J architecture with examples found here
- LLAMA – Based off of the LLAMA architecture with examples found here
- MPT – Based off of Mosaic ML’s MPT architecture with examples found here
and further:
How does GPT4All make these models available for CPU inference? By leveraging the ggml library written by Georgi Gerganov
the ggml library is reference to llama.cpp.
Using llama model with GPT4All
I wanted to run Vicuna with privateGPT. To do that I first tried using a LlamaCpp model type but ran into this issue. You may not run into this issue. It turns out you can run a Llama model using GPT4All since it uses same llama.cpp underneath as LLamaCpp. The steps to use GPT4all to run a LLama model are as follows:
- first I uninstalled
gpt4allandlangchainand installed following versions:gpt4all==0.3.4, langchain==0.0.202 - Then download vicuna from here.
- edit
MODEL_PATHin.envfile to point to the file in step 2 and setN_CTX=2048as vicuna uses a 2048 context size
Here is complete .env file:
PERSIST_DIRECTORY=db
MODEL_TYPE=GPT4All
MODEL_PATH=/llm/llama.cpp/models/gpt4-x-vicuna-13B.ggmlv3.q5_1.bin
EMBEDDINGS_MODEL_NAME=all-MiniLM-L6-v2
MODEL_N_CTX=2048
TARGET_SOURCE_CHUNKS=4
That’s it! You can now run vicuna with privateGPT.
One limitation is that the pre-built llama.cpp binaries that come with gpt4all don’t utilize the GPU on Mac. So inference is very slow. To fix this:
1. you can build llama.cpp yourself as explained here (make sure you also use the -DBUILD_SHARED_LIBS=ON flag with cmake otherwise you won’t get .dylib in the output; you will need to install cmake as well) and
2. replace the binary in venv/lib/python3.10/site-packages/gpt4all/llmodel_DO_NOT_MODIFY/build with your custom build. DO THIS WITH CAUTION. Make a copy of the old binary in case something goes wrong and you need to restore it.
