
Concurrency control is one of the key things to understand in any database. It is the I in ACID. From MySQL docs (applies to Postgres as well):
the isolation level is the setting that fine-tunes the balance between performance and reliability, consistency, and reproducibility of results when multiple transactions are making changes and performing queries at the same time.
The SQL standard defines 4 isolation levels. From PG docs:
Table 13.1. Transaction Isolation Levels
| Isolation Level | Dirty Read | Nonrepeatable Read | Phantom Read | Serialization Anomaly |
|---|---|---|---|---|
| Read uncommitted | Allowed, but not in PG | Possible | Possible | Possible |
| Read committed | Not possible | Possible | Possible | Possible |
| Repeatable read | Not possible | Not possible | Allowed, but not in PG | Possible |
| Serializable | Not possible | Not possible | Not possible | Not possible |
Ideally we would like to use the Serializable level but as we go down the list, the perf (tx throughput) takes a hit. However what would you rather have – a buggy system or one with higher throughput?
Let’s understand these isolation levels in more detail.
Read Uncommitted
Do not bother. Do not use. In fact PG does not even support it.
Read Committed
I like to think of Read Committed = No Isolation. More accurately Read Committed isolates a transaction from uncommitted changes of another transaction. Read Uncommitted provides no isolation of any sort. It is not necessarily bad to have your tx not isolated from (committed changes of) other txs (depending on the context). What it means is that you always get to see the latest (committed) state of the database. You are never working with stale data. The database is effectively not doing any concurrency control. All concurrency control is up to you by making use of LOCK, SELECT FOR SHARE or SELECT FOR UPDATE statements. Think of this mode as what you would do if you were doing multi-threaded programming with in-memory data structures.
Repeatable Read
Repeatable read is great for avoiding write conflicts (lost updates). If your transaction attempts to write to a row which was modified by another transaction, your transaction will abort when you try to commit it. This is a form of optimistic locking or MVCC. It is built into Postgres when using this setting and you don’t have to do MVCC at application level. Postgres does not block txs or lock any rows under repeatable read (do not ask for permission). It checks the version of the row when you try to commit your tx and if this version does not match the version when the tx started, it will auto-abort the transaction (ask for forgiveness). The application should catch the exception and then retry the tx.
You might think this is the best setting but the problem with repeatable read is that your application might be working with a stale copy of the data. Let’s say you read a value from the database and are using that to make a decision on what something else should be i.e., y = f(x). Your x can be stale. If no other tx has modified y, your tx will be able to modify y but you have made the decision based on outdated value of x. This problem is known as write skew. See wikipedia for a great example. One way to fix it is to use the FOR SHARE clause when you read x. The FOR SHARE clause will prevent any other tx from modifying x by placing a lock on it. Other txs will still be able to read x.
FOR UPDATE will also block any tx from reading x. Use FOR UPDATE when your tx will also be updating x, not just reading it and you want other txs to wait until you have updated x to its new value.
Repeatable read is a good setting when you have to make backup for example.
You might read the term snapshot isolation. Snapshot Isolation (or MVCC) is the technique by which Postgres implements Repeatable Read. Same principle is used in MySQL (double-check).
Serializable
The docs provide an example of a bug that cannot be handled with Repeatable Read or Read Committed levels unless you lock the table with LOCK command (read section 13.2.3). The Serializable level is implemented in Postgres using SSI = Serializable Snapshot Isolation. This technique uses optimistic locking like MVCC and does not cause any blocking or locking (wait…it does use predicate locks). It asks for forgiveness. It is best to think of SSI as an extension of MVCC. MySQL on the other hand implements Serializable using locking (more on it in later section). Like Repeatable Read, your application should be prepared for your transaction to abort in case of concurrency conflicts and should retry the tx in case of exception. Much more info can be found on Postgres wiki.
What level is the best?
I do not think there is a black and white answer to this question otherwise we would just use that level and don’t have to bother with anything else. End of story. I was reading the book High Performance MySQL and authors say they have rarely seen Serializable used in practice (because of the perf hit that in turn is because of locking). Also from MySQL docs:
The levels on the edges (SERIALIZABLE and READ UNCOMMITTED) change the processing behavior to such an extent that they are rarely used.
On the other hand I think a case could be made why use Repeatable Read when we know for a fact that it suffers from the problem of write skew? See this for another great example of the bug caused by REPEATABLE READ. Either use Read Committed and handle all the concurrency control yourself or use Serializable and let the database handle all of it. What’s the point of doing it half and half with Repeatable Read?
Postgres docs seem to nudge the user towards using Serializable. The docs say this regarding repeatable read:
Attempts to enforce business rules by transactions running at this isolation level are not likely to work correctly without careful use of explicit locks to block conflicting transactions.
and they do give an example of the bug that cannot be handled with Repeatable Read or Read Committed levels unless you lock the table with LOCK command. The docs then go onto saying this regarding Serializable:
The monitoring of read/write dependencies has a cost, as does the restart of transactions which are terminated with a serialization failure, but balanced against the cost and blocking involved in use of explicit locks and
SELECT FOR UPDATEorSELECT FOR SHARE, Serializable transactions are the best performance choice for some environments.
So I think in the end its up to the developer and what matters more. Are you looking for simplicity and correctness willing to pay in terms of perf? Choose Serializable. Do you think you can handle concurrency yourself? Consider Read Committed. As MySQL docs say:
Expert users might choose the READ COMMITTED level as they push the boundaries of scalability with OLTP processing
Recap of Concepts (specific to PG)
Snapshot Isolation = MVCC = Repeatable Read = No locking = No blocking. suffers from write skew
Read Committed = No Isolation (you manage concurrency yourself)
Locks = blocking. SELECT FOR SHARE and SELECT FOR UPDATE acquire locks.
Serializable = Serializable Snapshot Isolation = No locking = No blocking
Differences from MySQL
In MySQL, Serializable is like REPEATABLE READ, but InnoDB implicitly converts all plain SELECT statements to SELECT ... FOR SHARE if autocommit is disabled. If autocommit is enabled, the SELECT is its own transaction [ref]. Exercise: convince yourself this is exactly what you need to prevent the write skew from happening when using Repeatable Read.
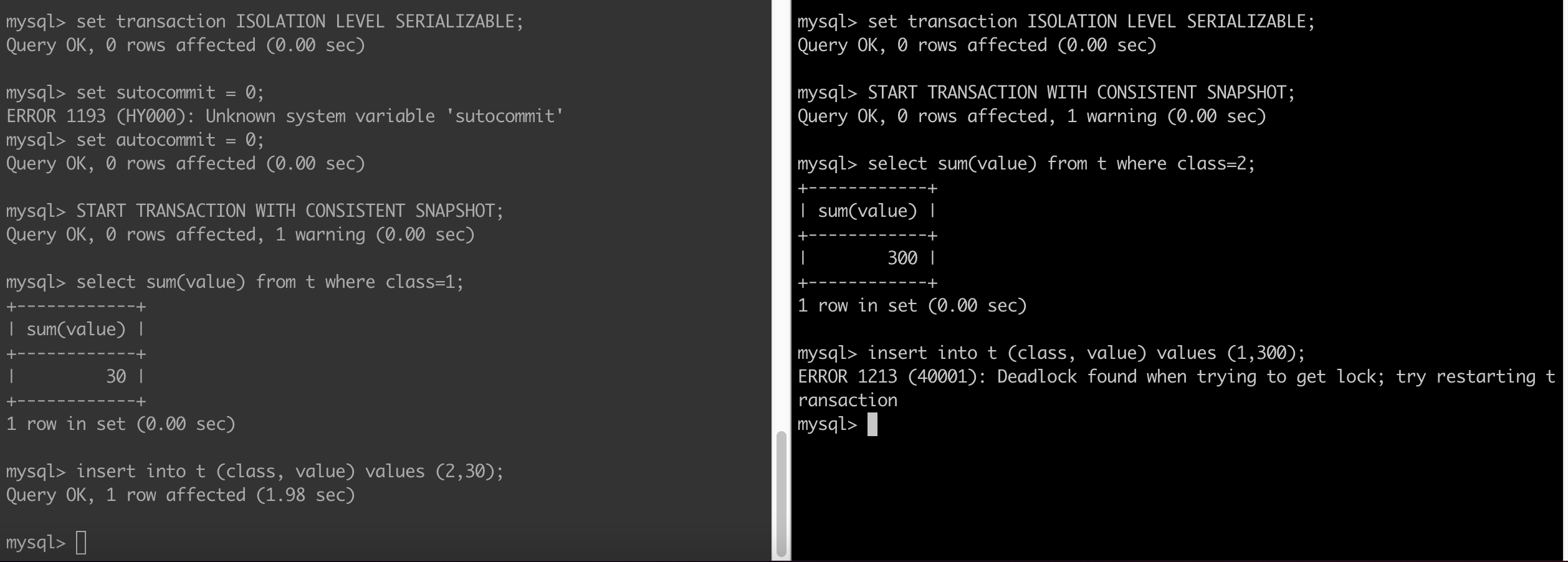
It is very instructive to compare the difference between Postgres and MySQL when using the SERIALIZABLE level using the example in section 13.2.3. You get the same end result but the internals are different. In case of PG there is no locking (refer docs) whereas in case of MySQL there is locking which manifests itself as one transaction waiting on another to complete as seen below:
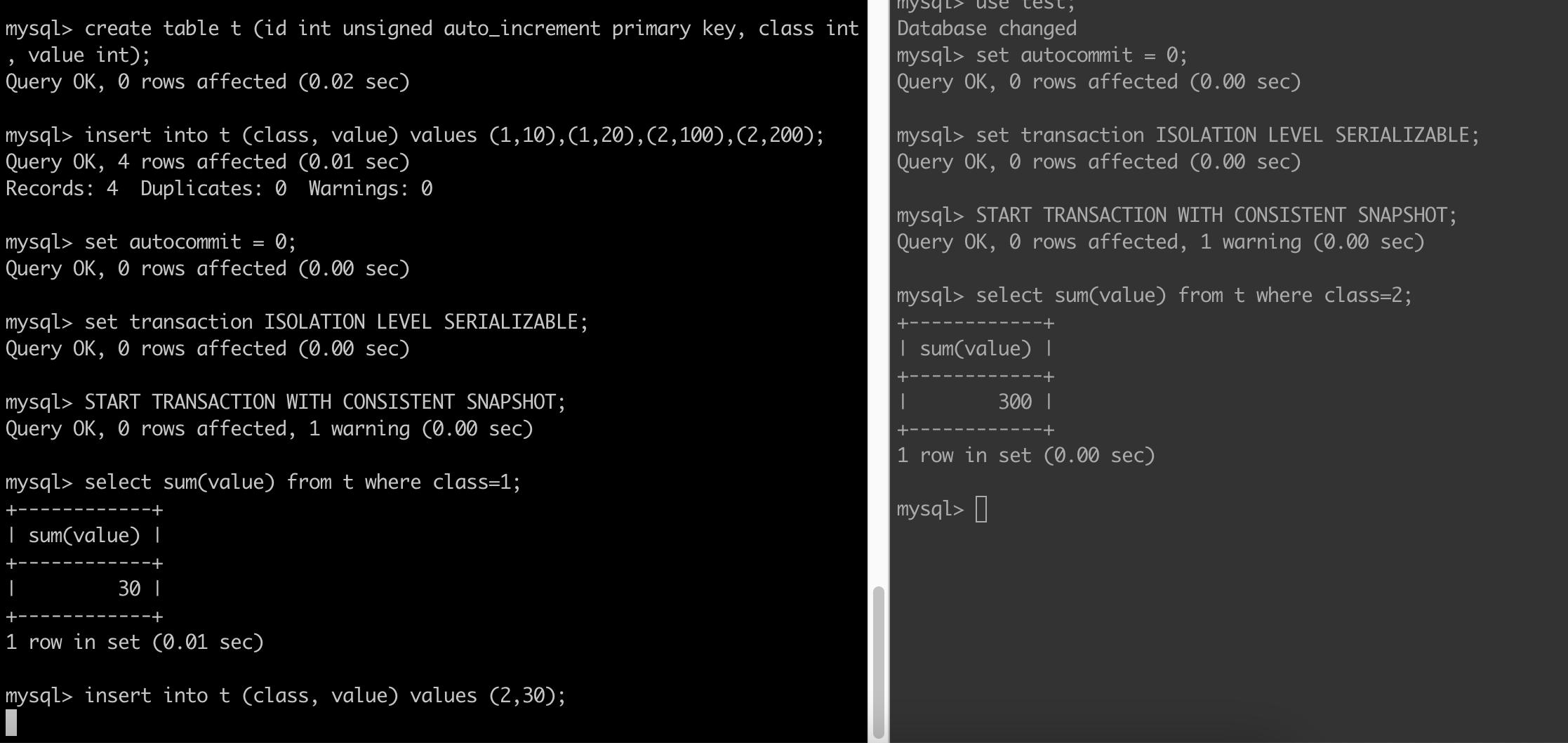
After sometime you will get a deadline exceeded error:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
If both transactions try to commit, MySQL will detect a deadlock and abort one of the transactions:
A Final Note
Note that SELECT...FOR SHARE and SELECT...FOR UPDATE do not work with aggregate clauses in Postgres:
postgres=*# select sum(value) from concur_test where class=1 for share;
ERROR: FOR SHARE is not allowed with aggregate functions
How do we protect against serialization anomaly with lower isolation levels?
Using a lower isolation level than Serializable does not mean that you are allowed to ship bugs in the code. What it means is that you will do extra coding to ensure there is no concurrency bug. Let’s take the example of the serialization anomaly in section 13.2.3 and see how we would avoid it with a transaction running with READ COMMITTED isolation level. I first thought of locking the table in SHARE lock mode. But it gave me unexpected behavior. See screenshot below:

The insert call on LHS is blocked. What happened?
- The
SHAREmode is not self-conflicting so both transactions were able to acquire that lock. - The
insertcall to a table acquiresROW EXCLUSIVElock and ahaROW EXCLUSIVEconflicts withSHARE. Since the second transaction has aSHARElock on the table, the first tx cannot move ahead. It has to wait until the second transaction releases its lock.
What would happen if the second transaction also tries to make an insert? If you guessed deadlock you would be right:

Both txs are now waiting on each other. Postgres detects the deadlock and aborts one of the tx with this message:
DETAIL: Process 13115 waits for RowExclusiveLock on relation 16884 of database 14020; blocked by process 12516.
Process 12516 waits for RowExclusiveLock on relation 16884 of database 14020; blocked by process 13115.
The other tx goes ahead and is able to finish its insert.
Ok, so this is a bug I made but how to fix this problem really. so far we haven’t solved the problem we set out to solve. Lets see what happens if we try to use SHARE ROW EXCLUSIVE lock mode:

The SHARE ROW EXCLUSIVE lock mode conflicts with itself. The other tx cannot acquire it while first tx is holding on to it. The second tx now has to wait (i.e., is blocked; has to wait for permission) for the first tx to finish. In this way the two txs are serialized now. Problem solved.
Dealing with concurrency is hard. Very hard. Developing databases is harder.
