
There are many online articles touting the advantages of non-blocking I/O over blocking I/O. But I wanted to see the difference for myself. So to do that, I developed an application two ways: one using Spring WebMVC + JPA which uses blocking I/O and another using Node.js which uses non-blocking I/O. MySQL database was used in both cases. In case of Node.js I used the Sequelize ORM. Spring JPA uses Hibernate ORM. I wanted the application to be complex enough to mimic a real-world scenario so the test results could be meaningful. Thus our application makes use of transactions, locking and SELECT, INSERT as well as UPDATE statements. In fact, I also made use of protocol buffers and there is some message decoding that happens in the application before it can process a message.
Problem Description
We consider a fictitious company selling some sort of products and what we want to do is to compute half-yearly sales of each product. E.g., imagine Toyota selling cars and it wants to calculate how many Toyota Corollas were sold in H1 2022 (H1 stands for first-half of the year) or Microsoft selling Office Subscription. For this we create 2 tables – one stores each booking or sale and another stores the aggregate sales divided over the different fiscal periods. The details of the tables are given below but not important. What is important is that we execute INSERT statements on the bookings table for each new sale. And need to INSERT or UPDATE values in the aggregates table. Further the operations need to be wrapped in a transaction and we also have to lock rows in the aggregates table using SELECT FOR UPDATE before updating them. So you can see we are not developing a trivial or toy application.
Bookings Table
+--------------+---------------+------+-----+-------------------+-------------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+---------------+------+-----+-------------------+-------------------+
| row_id | int | NO | PRI | NULL | auto_increment |
| booking_id | varchar(255) | NO | | NULL | |
| created_at | timestamp | NO | | CURRENT_TIMESTAMP | DEFAULT_GENERATED |
| dollar_value | decimal(19,2) | NO | | NULL | |
| end_date | date | NO | | NULL | |
| origin_ts | timestamp | NO | | NULL | |
| parent_id | varchar(255) | YES | | NULL | |
| trim | varchar(255) | NO | | NULL | |
| model | varchar(255) | NO | | NULL | |
| stage | varchar(255) | YES | | NULL | |
| start_date | date | NO | | NULL | |
| type | varchar(255) | YES | | NULL | |
+--------------+---------------+------+-----+-------------------+-------------------+
12 rows in set (0.00 sec)Aggregates Table
+---------------------+---------------+------+-----+-------------------+-------------------+
| Field | Type | Null | Key | Default | Extra |
+---------------------+---------------+------+-----+-------------------+-------------------+
| row_id | int | NO | PRI | NULL | auto_increment |
| version | int | NO | | NULL | |
| last_updated | timestamp | NO | | CURRENT_TIMESTAMP | DEFAULT_GENERATED |
| model | varchar(255) | NO | | NULL | |
| trim | varchar(255) | NO | MUL | NULL | |
| total_dollar_amount | decimal(19,2) | NO | | NULL | |
| fiscal_period_id | int | NO | MUL | NULL | |
+---------------------+---------------+------+-----+-------------------+-------------------+
7 rows in set (0.00 sec)I actually make use of a 3rd table to store data about the fiscal period and the fiscal_period_id is a FK to a row in that table. So we see the data model – while not rich enough – is hopefully complex enough for a perf test to be meaningful and mimic real-world scenario.
Deployment and Test Setup
Both the Java and Node.js app were deployed on GCP using Cloud Run. Both apps ran on a VM with 4 CPU cores and 4GB RAM (--cpu=4 and --memory=4Gi). In case of Java app I set the # of app instances to 1 whereas in case of Node.js we use 4 app instances to cover all the 4 CPUs available. Java app would use threads to max out the CPU resources available.
For testing I used JMeter and configured it to mimic 500 concurrent users (500 threads) making requests as fast as they can. In all total 50,000 requests were made (100 requests per user).
And what do we get?
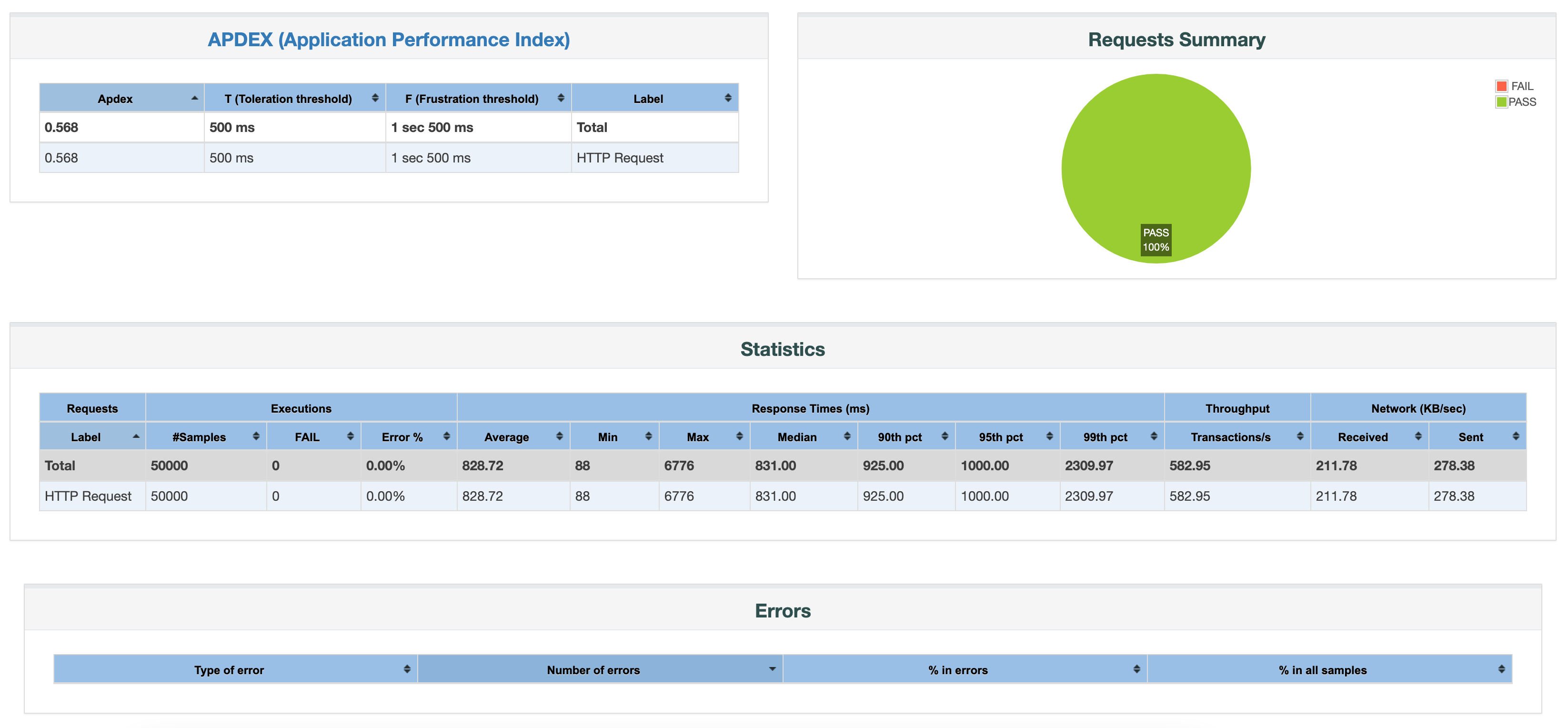
Java Spring WebMVC + JPA (Blocking I/O)
The results were quite impressive. The application was able to handle the load of 500 concurrent threads and not a single request failed. It blew away my expectations. Overall I got:
582 requests per second with 831ms median response time
Node.js with Express, MySQL2 and Sequelize
842 requests per second with 432ms median response time
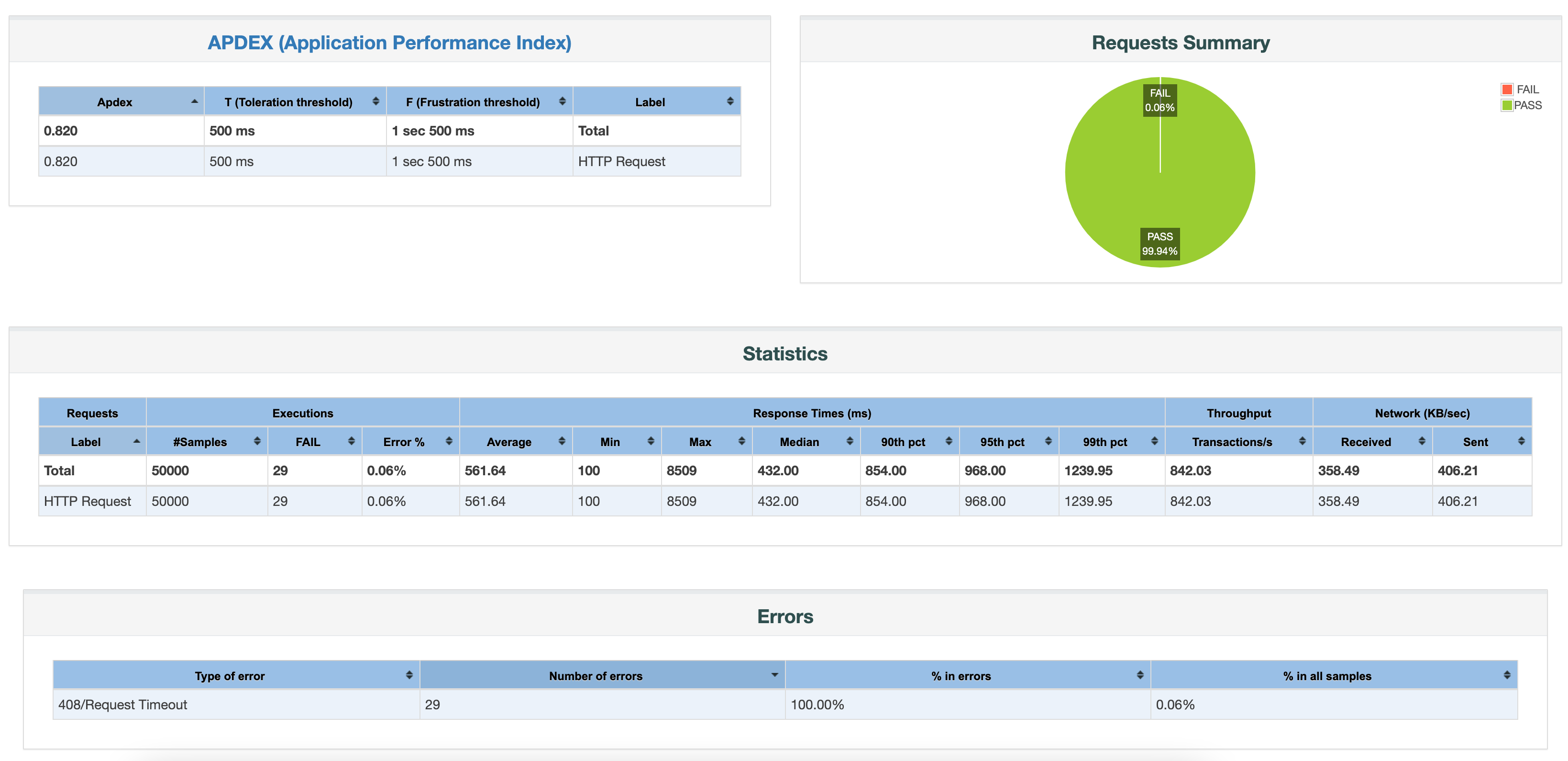
There are 29 requests that failed out of 50,000 due to request timeout.
What do I make of it?
Node.js performed better but the difference is not what I would call as staggering.
Node.js gives a 40% higher throughput than Java and confirms the rule of thumb – for I/O bound applications Node.js will perform better with its non-locking I/O whereas for CPU bound applications Java will perform better. The result is also inline with another study described here (this post motivated me to do my own test) where it was found that Spring WebFlux + R2DBC gave 30% higher throughput than Spring Web MVC + JDBC at high concurrency. That test was conducted using PostgreSQL database by the way – the database used and its driver can make a huge difference in the results. I feel the 40% increase we observed is significant enough for a mission critical application. It might not be overwhelming enough to warrant re-writing an existing application, but significant enough to tilt the balance in favor of Node.js when developing a greenfield application. Of course, there may be other things you want to consider such as library and data-structures support (Node.js comes with only two data structures – arrays and dictionaries) while performing a full evaluation.
What about non-blocking I/O in Java?
IMO Java is currently trying to add support for asynchronous and non-blocking calls to MySQL. The effort is part of a bigger movement towards reactive programming. From spring.io/reactive:
Reactive systems have certain characteristics that make them ideal for low-latency, high-throughput workloads. Project Reactor and the Spring portfolio work together to enable developers to build enterprise-grade reactive systems that are responsive, resilient, elastic, and message-driven.
There are two libraries in Java for making async calls to MySQL: jasync-r2dbc-mysql and r2dbc-mysql. A third option is vertx-mysql-client but its not based on R2DBC and does not integrate with Spring. I tried using all three but ran into issues. The r2dbc-mysql project is not being actively worked on in fact and hasn’t even matured to a 1.0 release. The other library is also not used extensively in production (at least that’s what it seems like to me) and developed by an independent developer without the backing of a large enterprise company. New code seems to be released without any testing. There were cases where a bug was reported, the developer quickly made a release with the bugfix but introduced another bug in the process. In fact, the r2dbc-spi (the Service Provider Interface that defines the API that drivers have to implement) itself is very recent and only achieved the 1.0.0 milestone on Apr 25 this year (2022). And this is not the end. The Java community is currently working on Project Loom which will bring coroutines (lightweight user-mode threads managed by JVM, not the OS) to Java (analogous to goroutines in Go) and eliminate the distinction between synchronous (JDBC) and asynchronous code (R2DBC). So the R2DBC technology of today will be supplanted by another API eventually and the programming model might change again. R2DBC might not become JDBCs successor after all. With vertx-mysql-client I ran into this issue.
To me, what this means is that for asynchronous and non-blocking I/O we are better off with a technology like Node.js.
For further reading, refer this related article which has a very similar setup except that it uses non-blocking I/O on Java side and further uses MongoDB. It reports identical performance between Java and Node.js when both are using non-blocking I/O with MongoDB.
Also see This website for spring-jpa vs. node.js:


Their database is PostgreSQL in case of spring-jpa and MySQL in case of Node.js. It contains many more benchmarks.
