
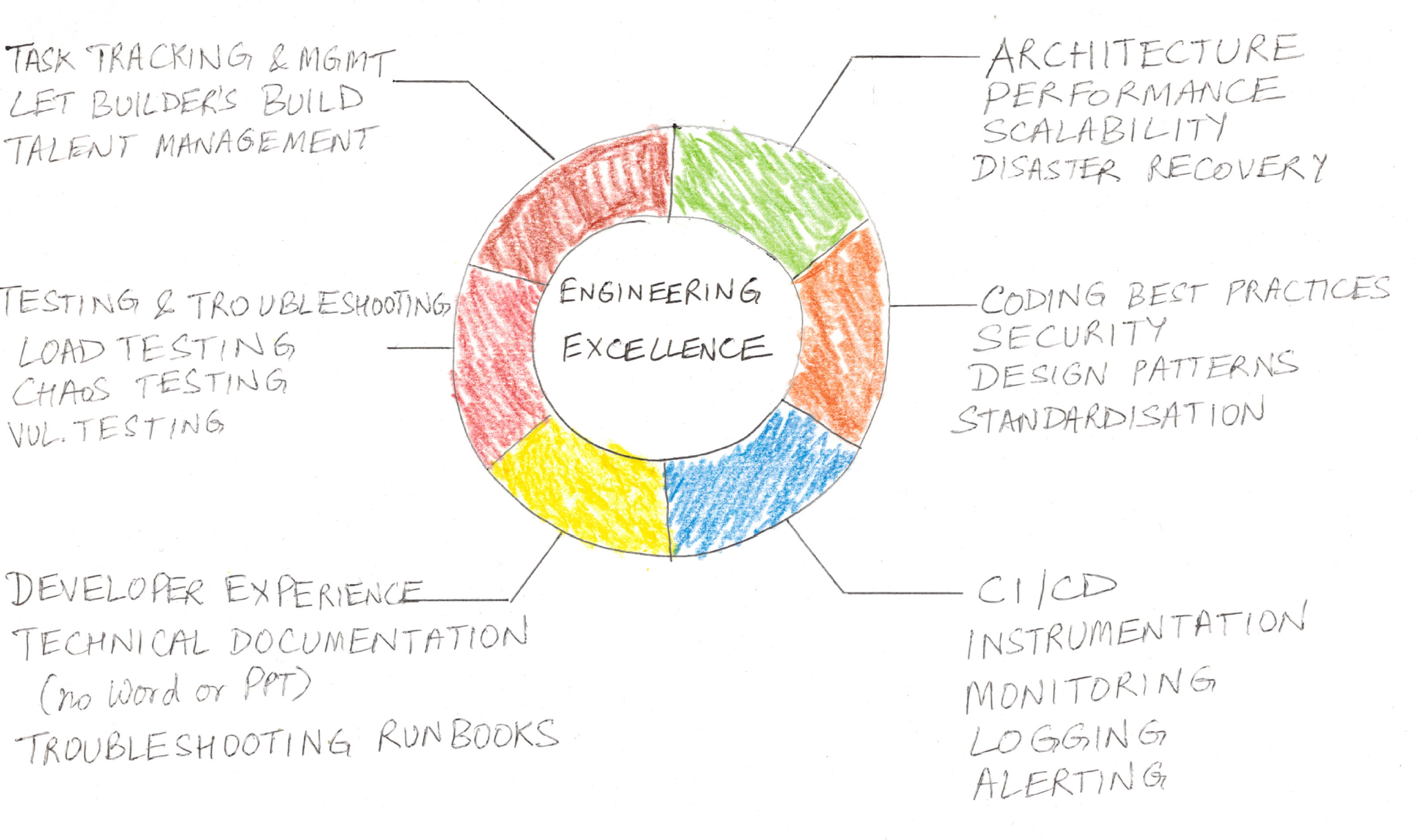
What is Engineering Excellence? EE to me is the passionate pursuit of perfection and its really about taking pride in what we build. EE to me is about code quality, developer experience, technical documentation, instrumentation, performance and scalability. It is not about maximizing the # of commits we make every day. If you measure your team velocity by the # of commits / day, that’s a wrong metric. Team velocity should be measured by the time it takes to make a release. EE avoids taking shortcuts and incorporates security best-practices etc. Because of this, it can be at odds with release velocity. Below is a checklist you can use to evaluate where you stand when it comes to EE:
- Do you have a code repository?
- Do you have an efficient code-review process? What is your check-in policy? I have a simple code-review policy. Code is assumed to pass review if # of approvers > # of rejects. Developers are pesky when it comes to reviews and requiring approval from everyone leads to nasty quarrels.
- Are PRs linked to work items in a task tracking system like JIRA etc.?
- Do you have policies in place that protect your public branches (master, release etc.) from malicious pushes (commits)?
- Do you follow trunk based development?
- Do you have CI? To me, CI comprises 4 things:
- A PR is automatically rejected if its not on top of latest code in the master or main branch (
--ff-only)
- Every PR triggers an automated build and associated tests whose results can be viewed by reviewers
- Every commit triggers an automated build and other validation tests
- Bonus: Bad commits are automatically rolled back
- A PR is automatically rejected if its not on top of latest code in the master or main branch (
- Do you squash PRs (
git merge --squash --ff-only) and delete PR branches? - Do you have a deployment pipeline? (Azure Pipelines, Bitbucket Pipeline, Jenkins etc.). Deployments don’t have to be automated but is there a one-click deployment process?
- Do you have a deployment dashboard where deployments can be rolled back?
- Do you have 3 deployment environments – dev, qa, prod?
- Do you use federated IAM? (the defining characteristic of federated IAM is that your application never sees the user’s password)
- If not, do you salt and hash passwords?
- Do you use service accounts / managed identity?
- Do you use a secret manager / Key Vault for storing passwords, private keys, tokens and other secrets?
- Are your secrets periodically rotated?
- Are you checking in passwords / secrets into source control? (answer should be no)
- Do your developers have write privileges to production databases?
- Do you have Role Based Access Control (RBAC)?
- Do you mask sensitive data (PII, restricted, HIPAA etc.)?
- Do you have data backup, disaster recovery, geo-replication and data loss prevention? Have you tested it?
- Do you have audit-logs to investigate unauthorized access to data?
- Do you have a troubleshooting runbook (SOS manual) that can be relied upon during on-call? Do you keep it up-to-date? Is it written in Markdown?
- Do you have a README.md in your repo that explains a new developer how to install all dependencies and pre-requisites, get permissions, build, run, debug, test and deploy the code?
- Do you use Microsoft Word and Sharepoint for technical documentation? (answer should be no)
- Do your developers spend more time in Powerpoint and less time in Markdown and Graphviz? (answer should be no)
- Do you test your unhappy code path (the code in the catch block)?
- Have you tested all possible error conditions (things that can go wrong)?
- Bonus: Do you perform chaos testing?
- Are your applications instrumented? Do you have an application performance monitoring dashboard where you can monitor resource usage, traffic, latency etc.?
- Are you testing your webapps using webpagetest.org or another such tool?
- Are you logging and alerting on 5xx errors and unexpected exceptions?
- Are your APIs gated behind a rate-limiter?
- Do you perform any static code analysis (SonarQube)?
- Do you check your dependencies for vulnerabilities?
- If using mocks, are you aware that code that is mocked is effectively not tested and should therefore be excluded from code-coverage? This is why I hate mocking. Mocking hides problems in the code and gives false sense of security.
- Do you have an E2E test environment where there is absolutely no mocking?
- Bonus: are you doing test driven development?
- Bonus: are you doing automated UI testing (selenium)?
- Are you disposing off resources properly? Do you understand the dispose pattern in C# / Java? Difference between managed and unmanaged resources?
- Do you use connection pooling for database access?
- Are your REST endpoints / APIs formally documented?
- Are you using HTTP-JSON for public facing APIs and gRPC / Thrift etc. for internal APIs (microservices)? Public API = an endpoint called by a web or mobile application in response to user-interaction. Internal API = an API called by a program e.g., data ingestion pipelines.
- Do you have a fragmented architecture making use of disparate technologies or an integrated ecosystem?
- Instead of thinking of Performance! Performance! Performance! think Tests! Tests! Tests!
Further Reading
However, on a large team in an enterprise environment I often do not recommend artificially keeping a linear history – TOP VOTED ANSWER
However I still maintain my position of keeping a linear git commit history. It is easier to understand, analyze and troubleshoot with git bisect. Prior to git we used TFS. It automatically rejected a commit if the developer’s code was not synced to the latest. Yes there is a downside that you always need to sync to latest and test your changes are still good – there is extra overhead but I think worth it.
