
| Structured Data | Unstructured Data | Semi-structured data |
| – the best way to think of structured data is data that can be queried through SQL – Structured Query Language – this means data has a schema and is made up of typed primitives in SQL – string, integer, float, etc. – schema on write | – binary data that cannot be queried through SQL – images, video are perfect examples – schema on read. your program decodes the data. The program is Java, Python etc. not SQL as by definition unstructured data is data that cannot be queried via SQL | – think JSON – modern data warehouses are adding capability to query JSON in SQL. so semi-structured data is moving closer to structured data |
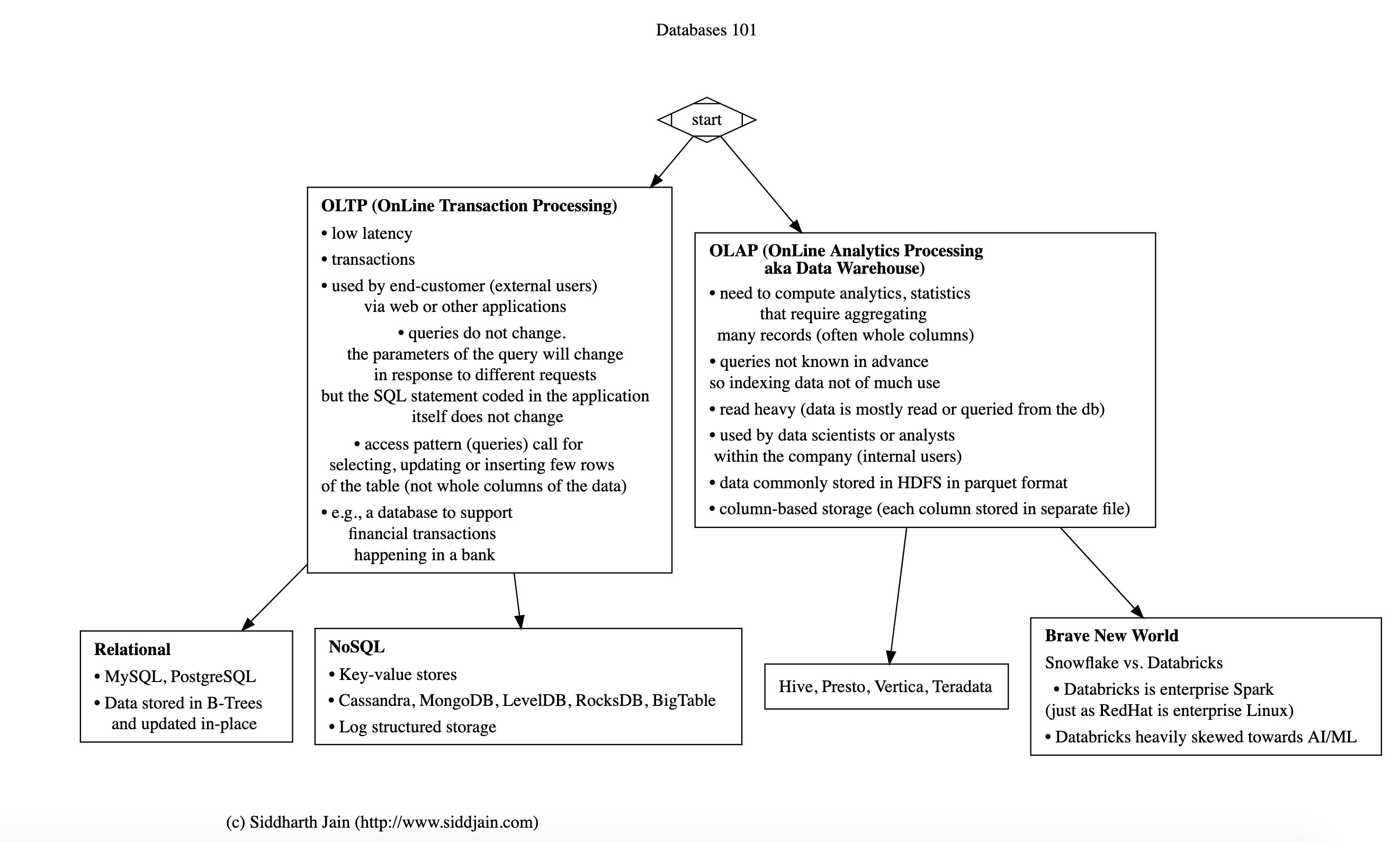
ETL, ELT and EL
- EL is nothing but bulk copying from one database to another. Read and Write as-is.
- ETL is Read, Process, Write. Spark jobs are ETL jobs. Spark is the modern incarnation of Informatica.
- ELT is Read, Write, Process or Copy and Process. This is a relatively new model being popularized by advent of databases with massively parallel compute such as BigQuery and Snowflake. The idea is to load the raw data into BQ and Snowflake and process the data in BQ or Snowflake itself. No need to use separate ETL tool like Spark. If you think about it BQ and Snowflake are running something like Spark underneath anyway.
In the end there is no winner or loser and the distinction is blurry. Chose whatever works for you. Don’t get tied up in marketing or latest “trends”. When viewed through the ETL vs ELT lens I see Databricks and Snowflake as non-overlapping in some sense. Databricks is for ETL whereas Snowflake is built for ELT and squarely competes with Big Query. The point to take away is that you will have many options when designing a new system and there is no right or wrong. All are good so long as you don’t choose a completely wrong technology for the specific use-case you are addressing.
Data Lake vs Data Warehouse
The distinction between a data lake and data warehouse is ill-defined at best and purely semantic. In principle data lake is meant to store raw data. Data warehouse stores processed data (ETL). Usually the distinction between raw data and processed data is not clear cut. If you have several stages of processing, what is the point or boundary where data ceases to be raw and classified as processed? Usually if a data analyst is consuming the data, then that’s the point where data is deemed to be processed and in a warehouse. Don’t get caught up in names. One thing for sure is that since data in a warehouse is meant to be queried in SQL, it is structured data stored in a database like BigQuery. But you can use BQ to store raw data as well (assuming its structured – you won’t store unstructured data in BQ) and use it as a data lake – a lakehouse in fact – lakehouse stores both raw as well as processed (transformed) data. This is enticing as you don’t have to store data in two different places. if it helps, think of data lake as being characterized by schema on read vs data warehouse as being characterized by schema on write.
| Data Lake | Data Warehouse |
| – S3, Google Cloud Storage – unstructured data. object store – file based API – data scientists who want to do ML over audio, video, images etc. – cheap, reliable storage – store vast amounts of (raw) data – schema on read | – Teradata, BigQuery, Snowflake – structured data – SQL – data analysts – expensive storage – ACID – used to power BI tools (Looker, Power BI, Tableau) – store curated data (since storage is expensive) – schema on write |
Databricks vs. Snowflake
The best way to understand the difference between Databricks and Snowflake is to go back to their origins and what they were originally developed for.
| Databricks | Snowflake |
| – A platform to run Spark jobs via Jupyter notebooks – for use by ML engineers and data scientists – process unstructured data – audio, video, images stored in file based object store | – data warehouse – for use by data analysts – process structured data (SQL tables) |
Nowadays the two are overlapping as both are going into the other’s turf but remember if you back in time, the two had very different audience and use-cases. This sentiment is reinforced here:
Snowflake (which historically comes from the structured data pipeline world)
Databricks (which historically comes from the unstructured data pipeline and machine learning world)
